
Picnic increasingly follows a data-driven approach towards serving content. Every customer sees their own version of the store, fitted to their needs and behaviors. While this enables a better user experience, it also places heavy demands on the flexibility of our store backend systems. The continuous introduction of new insights and data points, as well as the desire for business logic that can quickly evolve, introduces a set of challenges which are not easily solved.
Traditionally, at Picnic we’ve solved such challenges with custom backend implementations based on the required business logic. Every change then required development work, resulting in long feedback loops and significant iteration times. Ultimately this prevented us from quickly delivering a better experience to our customers. Ideally we have a platform that is as self-service as possible, enabling analysts and business operators to efficiently iterate on business logic themselves. Developer effort would then only be needed to evolve the platform, not to implement specific business use cases. In addition to quickly changing business logic, we also want new data sources to be readily available for maximum personalization.
In this blog we will take you through our approach to solving this problem, illustrated using a simple use case.
Setting the Goals
Imagine we’re asked to implement a basket recommendation feature for our app. Its goal is to suggest the most relevant products a customer could add to their basket before checking out. Implementing this feature involves many factors:
- If the customer orders eggs in every delivery, but doesn’t have any eggs in their basket, we may want to recommend them.
- If the customer already has bananas in their basket, we wouldn’t want to recommend other bananas.
- If a product is unavailable for a specific delivery time and location, we don’t want to recommend it, even if it might otherwise be relevant.
The data needed to make this selection would typically be distributed between multiple backend services; customer buying patterns live in the order history service, contents of the customer’s cart in the cart service, and product availability in the stock service. Each service exposes data through APIs that might differ per service. As these data points cannot be accessed uniformly, we need a processing layer to aggregate them.
One of the most straightforward ways to do this might be to build another backend service containing logic to combine the various data sources, then expose the result through an API endpoint. Figure 1 shows how this setup could look. Each service might use its own data source and APIs, so the new service will need to handle translating the incoming data flows.
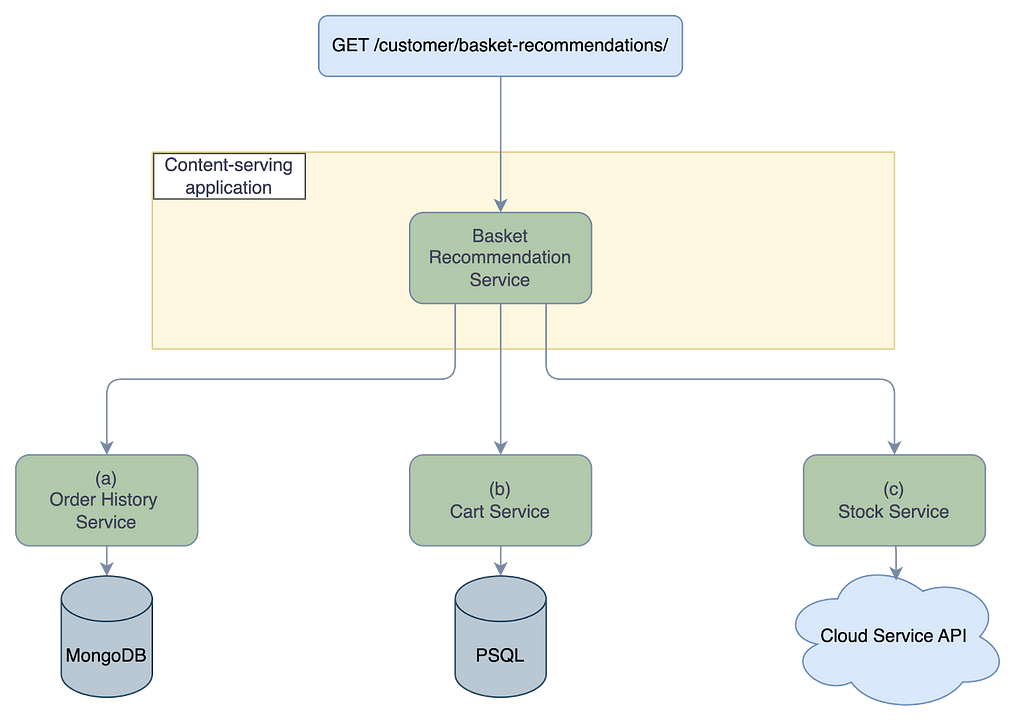
Many services are built in this way, but the challenge arises when we consider how this feature needs to improve and change over time. Basket recommendations are closely tied to business logic, which is iterative and frequently changes. For example, we might want to add seasonal recommendations like Christmas meals. We also might want to further personalize the recommendations based on the customer type and preferences. Additionally, we often run experiments for changes to the business logic, which complicates the setup even further.
Now, imagine we have multiple variations of this feature displayed in different parts of the store app, depending on different contexts. This approach becomes even more complicated and cumbersome to maintain when we think about future changes and iterations, especially while prioritizing flexibility and maximum personalization of store content for every customer. If the business logic is embedded within a backend service, any changes require backend development, which is bound to slow down business iterations.
Architecturally, the addition of new business logic can quickly lead to the growth of application complexity.
To illustrate how quickly the complexity can grow, see Figure 2. In this figure, we introduce a new module with a different use case but similar functionality (e.g., it also combines the same data sources, yet it might contain variations for how the result is filtered or grouped). To support this new use case, we would add everything shown by the solid lines.
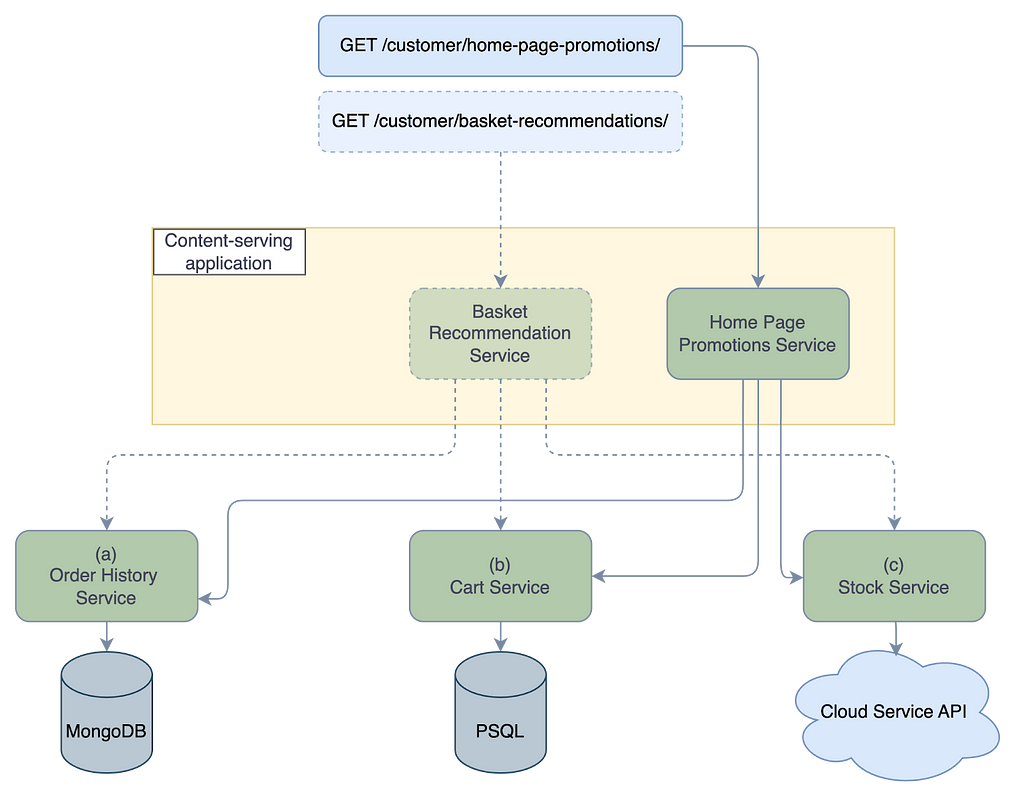
With just two relatively simple use cases, we’ve already ended up with quite a complex architecture. This complexity will keep growing as we iterate over existing features and add new ones. Additionally, this setup has limitations that don’t align with some of Picnic’s goals. We want to be adaptable, have short feedback loops, and empower analysts to configure and implement business logic without needing backend involvement. This setup doesn’t meet our needs, so let’s now take a moment to formulate our requirements:
Our Requirements:
- Access data through a unified API.
The data points are spread across various services. We need a unified API to access them. - Ease of use for analysts and support for quick business logic iteration.
A lot of our features are complex and require rapid iteration. It should be easy for analysts to make changes without involving developers. Backend iterations are slower due to manual development effort and release cycles, whereas changes from analysts are instant and independent. - Optimized for real-time data retrieval use-cases.
All required data is calculated in the “hot path” while a user has the app open, so they must be fast while still serving up-to-date data. - The available data pool can be easily extended with new data sources.
- Data should not be exposed to unauthorized viewers.
With these requirements in mind, we started searching for a framework that fit our needs. Our search led us to Apache Calcite. Let’s take a look at what Apache Calcite is and see how it meets the requirements we’ve set out to fulfill.
What is Apache Calcite?
Apache Calcite is described as a “dynamic data management framework” for Java. In other words, it allows for exposing data sources as SQL tables, regardless of their underlying implementation or storage format. An SQL query can then access and query tables similar to a real SQL database.
One of the core concepts in Apache Calcite are tables. A Calcite table represents a data source such as a database, file, data stream, etc, adapted to serve data as an SQL table. It is important to note that Calcite tables do not store any data themselves, but rather delegate data access to the underlying system, exposing them uniformly as rows in a table. Tables are identified by names and are exposed to queries as relational entities. It is possible to create custom tables by implementing Calcite’s interfaces. The implementation of a table defines how the data is accessed and processed during query execution. A key feature is that it supports JOINing tables, making it easier to combine data from different sources.
Note that access to the data of Calcite tables is read-only; insertion and management of the data exposed by Calcite tables is out of scope for the Calcite integration.
Modeling our use case using Calcite
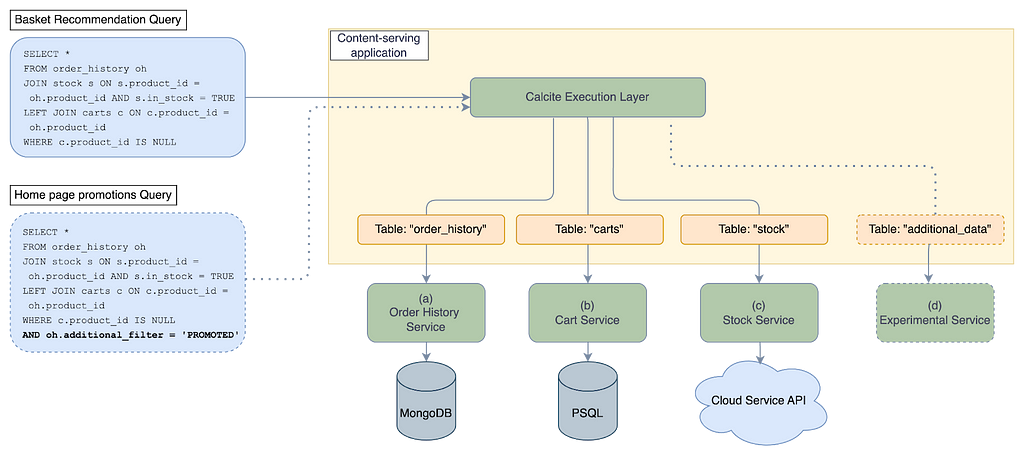
Let’s revisit our use case of supporting rapidly evolving business logic, while requiring less-frequent changes to data source integrations. This introduces a new distinction in the roles involved in developing a new feature: we have one role to provide access to required data sources, and another to write queries representing the business logic, as seen in Figure 3. Exposing and integrating new data sources remains a responsibility of backend developers. This is achieved by writing adapters that define the link between the services (the green boxes in Figure 3), and the “tables”. The logic of the aggregations performed on the data sources is externalized, represented by a query that runs against the backend service, instead of being defined within it. The externalization of the logic is shown by the blue boxes on the left in Figure 3.
With this setup, we allow analysts to write SQL queries that access data sources and perform logical aggregations to implement business logic, and reap the benefits and flexibility of SQL-like operations. We also allow the architecture of the service to become less complicated and more independent. The backend service becomes less of a contention point for developing business features and more of an engine enabling nearly unlimited use cases.
For our example use case of providing basket recommendations, we define Calcite tables for each data source needed to implement the feature. Each service is exposed as a table providing access to its data. We also provide an execution layer that can execute queries against the tables, allowing them to then be queried in different variations, as if interacting with a homogenous database.
We may then implement the basket recommendations feature with a query like:
SELECT *
FROM order_history oh
JOIN stock s ON s.product_id = oh.product_id AND s.in_stock = TRUE
LEFT JOIN carts c ON c.product_id = oh.product_id
WHERE c.product_id IS NULL
If we then want to implement a home page promotions feature, we may do so with a slightly tweaked query:
SELECT *
FROM order_history oh
JOIN stock s ON s.product_id = oh.product_id AND s.in_stock = TRUE
LEFT JOIN carts c ON c.product_id = oh.product_id
WHERE c.product_id IS NULL
AND oh.additional_filter = 'PROMOTED'
The queries above (which are also shown in Figure 3) are modifiable and extensible with no backend changes needed. The dotted lines in the figure show what is needed to add a new feature that requires adding data retrieval from a new service.
Looking back at our requirements, let’s see if Calcite achieves what we need:
- Easy aggregation of data retrieval across services: Calcite provides a unified interface for querying tables, regardless of the origin of those tables and what their backing data sources are.
- Ease of use for analysts and support for quick business logic iteration: Calcite is queried using SQL, which our analysts already have extensive experience with, and are comfortable quickly iterating with.
- Optimising data-retrieval/aggregation for real-time use cases: Out of the box Calcite may not be optimal for real-time use cases. However, it is highly extensible enough to allow us to build custom solutions on top of it, which ensure using limited APIs for accessing data, by customising tables to require API inputs.
- Simple registration of new arbitrary data sources: New Calcite tables can be easily registered in the schema by developers. Once a new table is added, it can be immediately utilized in new as well as existing queries to enhance their business impact.
- Security: Currently individual Calcite tables are responsible for handling their own security concerns, such as ensuring that private data from the backing data source is only exposed to those who are authorized to see it. We are in the process of improving this and delivering a more centralized solution, to make security management easier for developers.
Alternative solutions
Naturally, we investigated other options before we chose Calcite. We want to briefly share some of the considerations we took into account.
First we considered ease of use for analysts. While we have quite some tech-savvy analysts at Picnic, we aim to make it easy to use for them. SQL is something most analysts are already used to. This is one of the reasons why we chose not to use, for example, GraphQL, as it requires learning a new query language, as opposed to Calcite’s SQL interface. This also has the advantage that we can use common SQL operations such as COUNT and GROUP BY out of the box. Another disadvantage for using GraphQL is that it allows for less fine-grained control over query execution. For example, when using Calcite we can explicitly define the intended JOIN operations, and the query planner may further optimize the execution plan to achieve the best performance.
One of the other solutions we investigated was Backend for Frontend (BFF). There are a few reasons why this approach didn’t fit our requirements. First of all, backend responses are optimized for the unique requirements of a frontend application. Our use cases require exposing data to our application’s frontend, but we need to query for data from other, non-frontend contexts. Calcite fits our needs here as it is client-agnostic, and simply provides results for queries.
Additionally, we need to support rapidly evolving business logic with minimal impact on backend implementation. As such, coupling to specific frontends in a way that would require custom coding for them is something we want to avoid. Fortunately, Calcite’s generality means it also handles this situation well.
Conclusion
For Picnic’s analysts, the Calcite platform has been a huge productivity boost and boon for their way of working. Without any backend involvement analysts are able to write queries that determine business logic in all kinds of places. A good example is the Store, where analysts are able to write flexible queries that deliver personalized recommendations to our customers, and quickly iterate on their approach to doing so. We are also beginning to see use cases outside of the Store itself, with analysts using Calcite to solve problems such as determining which customers should receive a specific communication. Additionally, now that our analysts are becoming more comfortable with Calcite, they are introducing even more complex use cases which continue to deliver an improved shopping experience.
The introduction of Calcite was not without its challenges. Especially when ramping up the use of Calcite, we ran into challenges around excessive query planning, which was causing performance issues in the critical path of responding to customer requests. However, we were able to optimize and share query plans across our systems, resulting in significantly improved performance. This is something we may explore further in a future blog post. Another area with its challenges is query performance analysis, as our analysts frequently write complex queries that may be difficult to optimize enough to meet our latency requirements. We are beginning to explore solutions in this space, with the goal of providing self-service tools to enable anyone at Picnic to efficiently optimize their own queries. Lastly, while there are advantages to providing a unified abstraction layer on top of many data sources, this also means it is less clear what is happening under the hood. For example, it may not be immediately clear that a performance issue in a single service is slowing down an entire query, which makes troubleshooting more difficult.
In summary, Apache Calcite is a powerful tool that allows for seamless integration of diverse, disjoint data sources through a single API. It has enabled us to unify querying of services and databases across our systems without introducing complex backend logic. Since fully incorporating it into our business development flows, our analysts have enjoyed faster iteration and feature rollout than before, utilizing a SQL-based interface that they are already familiar with. This has enabled us to more quickly launch exciting features like our meal planner. As our systems evolve and become more complex, we are excited to continue leveraging Calcite’s capabilities to provide a better shopping experience for our customers.
This article is written together with Rick Ossendrijver, Enric Sala, Austin Richardson, Wegdan Ghazi.
This article is part of a series of blogposts on the architecture behind our grocery shopping app. Hungry for more? Chew off another bite with any of our other articles:
- In Faster Features, Happier Customers: Introducing The Platform That Transformed Our Grocery App, we share the motivation behind our architecture and give a general introduction.
- Define, Extract and Transform inside Picnic’s Page Platform gives a high-level overview of our journey towards a platform that enables querying data and transforming it into rendering instructions for the client.
- Picnic’s Page Platform from a Mobile perspective: enabling fast updates through server-driven UI details our approach to implementing server-driven UI in our mobile apps.
- In Tackling Configuration: creating Lego-Like Flexibility for non developers, we discuss the configuration tools we created on top of this architecture, allowing non-engineers to change the configuration of our Store.
Stay tuned in the coming weeks while we publish more blogposts in this series.
Enabling rapid business use case iteration with Apache Calcite was originally published in Picnic Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.

