
When people think of Large Language Models (LLMs), generative AI often comes to mind, especially with models like ChatGPT, Midjourney, and other tools taking the world by storm. However, some of the most valuable applications of LLMs lie in enhancing existing machine learning tasks with their advanced capabilities. In this blog post, we explore how we’ve recently started leveraging LLMs to enhance product and recipe search retrieval for our customers, making it easier for them to find exactly what they need.
At Picnic, we deliver groceries ordered from the palm of your hand right to your doorstep, which poses the challenge of accommodating tens of thousands of products in an interface smaller than almost anything you would find in a brick-and-mortar store. A critical tool in surmounting this challenge is our product search: from birthdays to Christmas parties, and from Lego to other Picnic-themed goodies, our customers use search to navigate our broad product and recipe assortment, with millions of different search terms being used in the process. Developing a search system that quickly delivers accurate results is no small feat, especially when serving customers across the Netherlands, Germany, and France — three countries with their own unique language and culinary preferences. With such a high volume of search terms, this is already an intriguing engineering challenge on its own; but when coupled with a customer base as diverse as their taste buds, this becomes a prime candidate for a solution backed by the latest in machine learning technology.
When going from search terms to finding products and recipes, you could think this is a pretty straightforward exercise, with a solution as simple as doing a quick lookup in a table. However, there are a lot of ways users behave which makes it that much more challenging. One person that looks for yogurt might make a spelling mistake and type “jogurt”, while the other might mean something else than they are actually typing. And this is not to mention the wide range of typos that can make it difficult to understand what the users mean: from double whitespaces between terms to typing accidents that add random letters to the search query. And: How do we make sure a customer looking for ice finds out that we do not sell blocks of ice, but do sell ice-making utilities? To achieve that you need a combination of a pretty interface and smart search retrieval tech.
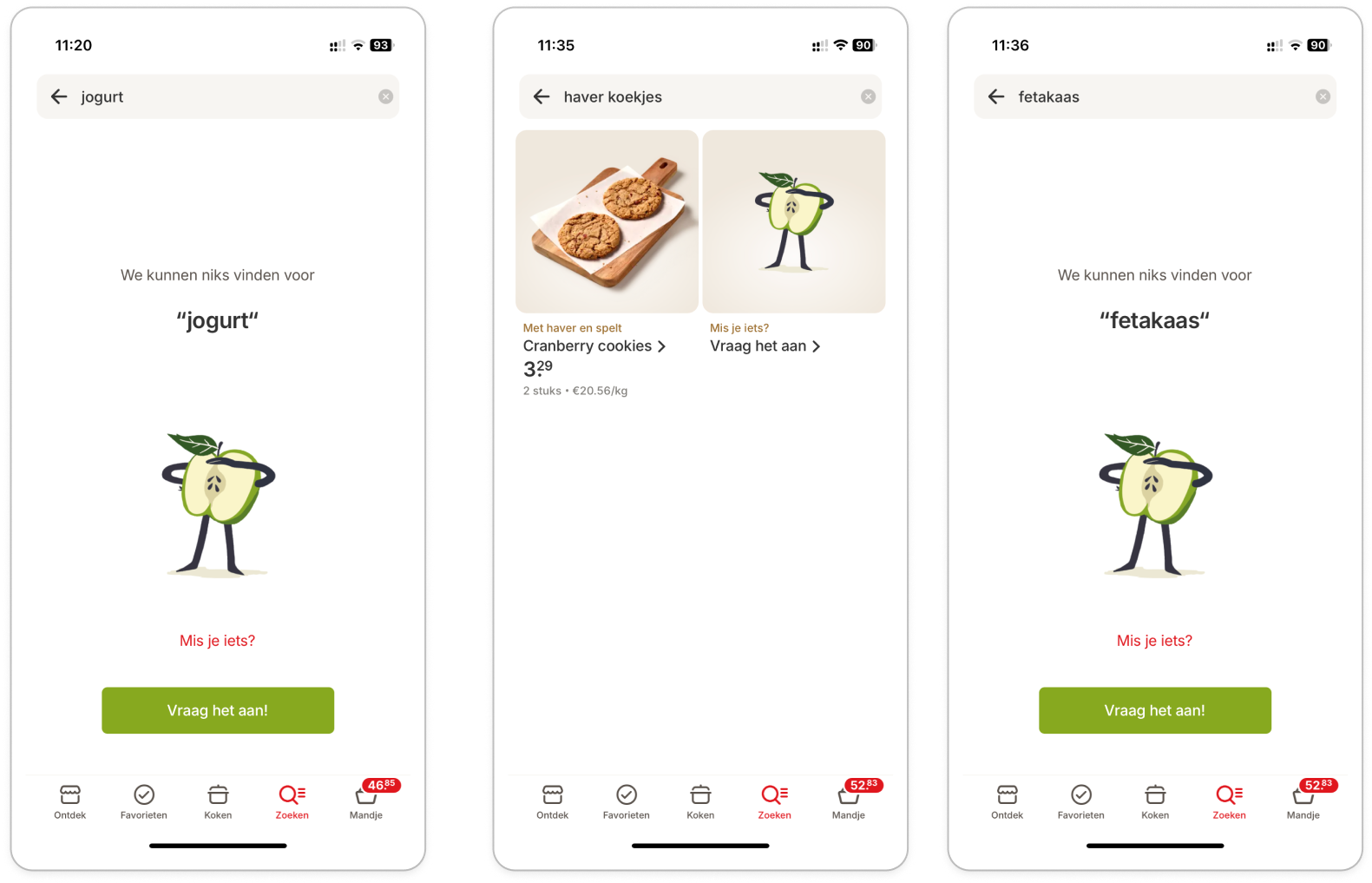
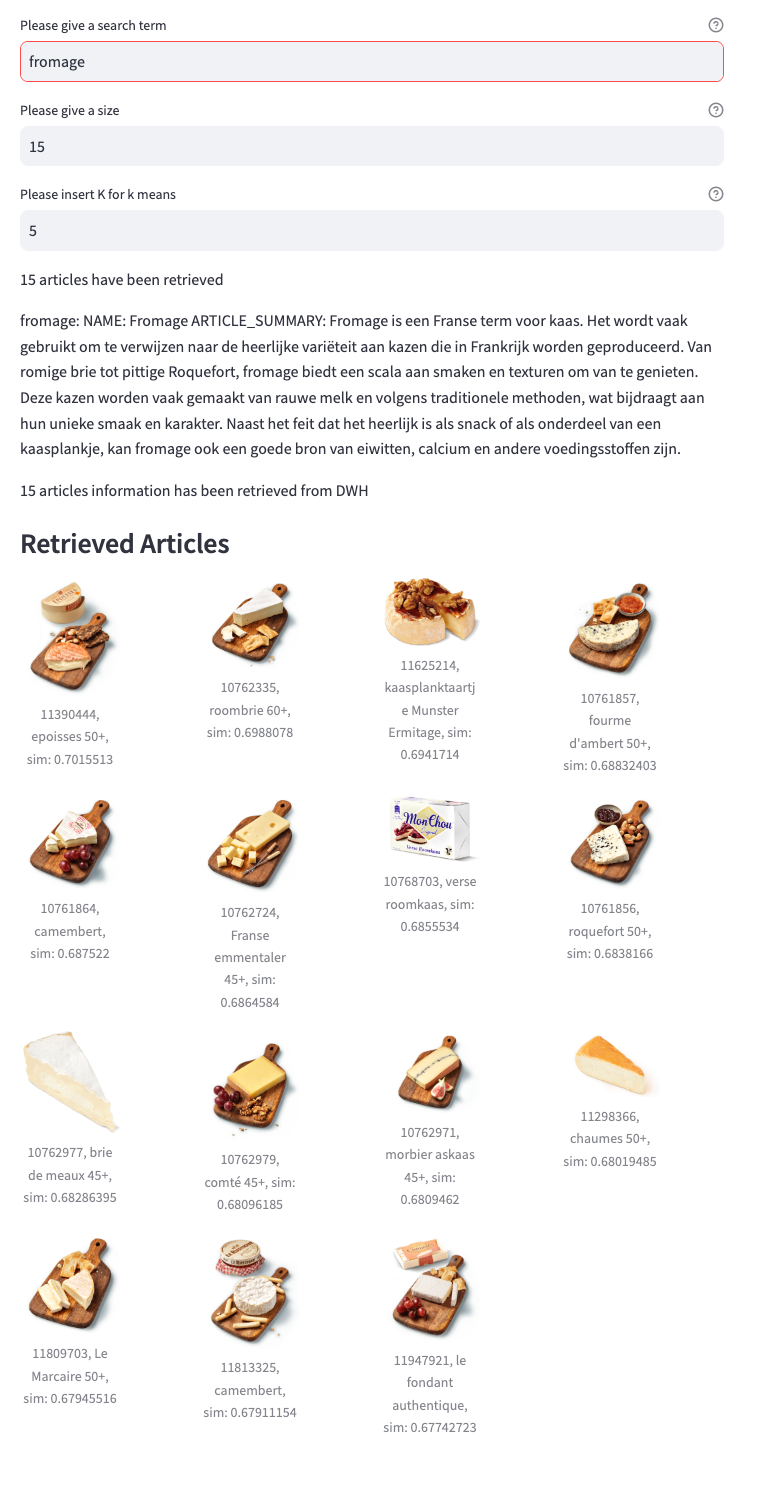
Fortunately, the use of AI and large language models has opened up a realm of possibilities. We recently explored these technologies to enhance our search capabilities. For example, how do we ensure that when our Dutch customers search for ‘fromage,’ they find French cheeses, while our French customers find what they expect simply by searching the same term? How do we create a system that avoids the typical slow responses of LLMs, which can take seconds, when our users expect results to appear as they type? And most importantly, how do we ensure that the search results truly meet our customers’ needs?
AI is Transforming Search
In the past, it was common for search systems on e-commerce sites to be subpar, and customers, aware of these limitations, were prepared to make multiple attempts to find what they needed. However, the expectations for search functionalities are much higher today, especially when customers are not just shopping for one-time purchases like a new phone or laptop, but are filling their weekly grocery baskets with a diverse range of products. They expect a best-in-class experience. As everyday interactions with highly advanced language models become commonplace, customer expectations for what technology can achieve are rising. And when our customers expect something, we work hard to make it happen.
Prioritizing Speed and Reliability
With millions of customers using our platform to do their weekly grocery shopping — aiming to save time otherwise spent driving to the supermarket and waiting in lines to check out — it’s crucial that the experience is fast and seamless. It’s vital for search results to appear more quickly than most LLMs can generate output, and thus we decided to go for precomputing common search terms. Eventually, we could fully unleash the power of LLMs to our customers, for which we could ask for help from one of the many talented designers working for Picnic because this would require a different user interface and a way to handle the slower response times of LLMs when doing none cached completion and retrieval tasks. But for this first version, we are keeping things quick and efficient.
What is Search Retrieval?

Search retrieval is a fundamental task that enhances our ability to link users with the most relevant content based on their search queries. The primary function of search retrieval is to efficiently navigate through large volumes of data — in Picnic’s case products or recipes and provide users with the most suitable results that align with their search intent. This process involves more than just fetching data: it’s about comprehending the context of a query and delivering results that are both pertinent and likely to meet the user’s expectations.
Our objectives in optimizing search retrieval are multifaceted: we aim to improve conversion rates by ensuring users find precisely what they are searching for, thereby encouraging deeper engagement with our platform. We also focus on enhancing the click-through rate, a clear measure of how compelling and relevant our search results are. Above all, our ultimate goal is to boost customer satisfaction. This involves refining our search algorithms to accurately interpret and process user queries, even correcting for common errors like typos or vague inputs.
Effective search retrieval not only increases the efficiency of our platform but also provides a seamless and gratifying experience for the user. They can effortlessly discover the content, products, or information they seek, leading to a more engaging and fulfilling interaction with our services. Achieving success in search retrieval is essential for maintaining a competitive edge and cultivating a loyal customer base.
So, what is our approach to search retrieval?
At the heart of our strategy is prompt-based product description generation. This basically turns a search term into a description that we can use to compare the search term to our entire product and recipe assortment. By harnessing advanced language models, we dynamically generate descriptions that capture the essence of articles and recipes, transforming search terms into detailed, actionable queries. For this we are using OpenAI’s GPT3.5-turbo model, as it performs just as well compared to its much slower brother GPT4-Turbo. This method not only enhances the accuracy of search results but also ensures that the content is closely aligned with user intentions. For instance: are you looking for what to buy for your daughter’s birthday party? Or preparing for a romantic dinner with a loved one? In any scenario, the prompt will convert your intentions to a description of products related to such an event.
Prompting and embedding millions of search terms is resource-intensive and there is a small fee for using the OpenAI APIs. To streamline this process, we precompute embeddings for search terms as well as for the content of products and recipes. Since we know what our customers have looked for in the past, it is easier to precompute 99% of search terms than to set up infrastructure and introduce dependencies that would not allow for milliseconds of latency. Precomputing allows us to quickly match queries with the most relevant content. In addition to improving search efficiency, we implement caching mechanisms throughout our system. This approach minimizes computational demands and energy consumption, reflecting our commitment to cost-effectiveness and environmental responsibility.
Additionally, ensuring 24/7 service uptime is important, requiring the intelligent management of third-party dependencies, possibly through effective caching strategies. At Picnic, we employ OpenSearch to deliver swift search results to our customers. OpenSearch provides a flexible, scalable, and open-source solution for building data-intensive applications, ensuring our service meets the high standards our customers expect.
Below is how we set this up in OpenSearch, using two indexes: one for the retrieval of search term prompts and embeddings, and one that is used afterward to retrieve embedding retrieval entities.
The output prompt is converted into embeddings using the text-embedding-3-small model from OpenAI. Why not the large model? Because for efficient retrieval the maximum dimensionality in OpenSearch is 1536 which is also the size of the output size of text-embedding-3-small.

Furthermore, we’ve integrated numerous sanity checks within our pipeline such as verifying if the embeddings are consistent and of the appropriate length. These checks are crucial for maintaining the integrity and consistency of outputs from language models, which can vary with updates and model iterations. Our use of OpenSearch plays a pivotal role in distributing these precomputed predictions and retrieving search results. This robust framework not only ensures that our search retrieval system is scalable and reliable but also capable of delivering precise and relevant information swiftly to our users.
How do we know if it works?
In the initial phases of our AI-driven search project, extensive offline optimizations form the start of our development process. Here, we manipulate search parameters, tweak LLM configurations such as prompts and dimension size, and experiment with different models to evaluate their potential impact on search accuracy and speed. This stage is critical for identifying the most effective combinations of technologies and strategies without affecting the production environment. However, since offline evaluation is done using past search results, the ground truth is not as clean as one might expect, and ideally, it is only used for the first tweaking of parameters.
And yet, by simulating a variety of search scenarios and challenges, we can refine the AI models to better understand and predict customer intent, ensuring that the transition to better capture user intent is seamless.
Following successful offline optimizations, we move to online A/B testing, a crucial phase where new features are introduced to a controlled group of users. This testing method allows us to collect valuable data on how real users interact with the changes compared to the existing system making it a much more reliable source of information to optimise the approach. Through making many iterations the system can be optimised to be the best possible, and we make sure we step in the right direction one step at a time.
Scaling Successful Innovations
Once A/B testing demonstrates the success of a new feature, we begin the process of scaling these enhancements across our entire user base. This phase involves careful monitoring to manage the increased load and to ensure that the integration maintains system stability and performance.
Scaling is also an opportunity for further optimization. As more users interact with the new features, additional data can be gathered, fueling further refinements and leading to even more personalized and accurate search results.
However, the first A/B tests are only the beginning. From changing the ranking to deciding how to mix recipes and articles, towards using more hybrid approaches that combine literal search with the new LLM-based search: there are millions of ways to configure the search results, and even more experiments to run and learn from
What is the future of search retrieval?
The future of search retrieval evolves as the intent behind users’ queries changes. Companies must adapt to keep pace with these shifts. The potential for innovation in this field is boundless, yet one thing remains clear: customers want to quickly and effortlessly find exactly what they are searching for.
Are you interested in working with the latest technologies and the cleanest data? We are actively seeking talented individuals for a variety of machine-learning engineering roles. Join us in shaping the future of search technology — find out more about these opportunities here!

