

The story of building an automated warehouse without having one — Part II
Note: This is Part II of the series. In Part I, we saw why building a simulation was the only way we could deliver a working final product on time.
First steps in The Matrix
Testing needs to feel real. In any field of engineering, it is used to improve products as much as possible before they are used by the general public. Car manufacturers perform real crashes to test for safety, bridge engineers use real vehicles to load-test the bridge before opening it. Software engineering is no different: our testing setup should be as close to production as possible. That is why our simulation needed to be like The Matrix: it had to feel like the real thing. But what does “real” mean for warehouse software?
Let’s lay the basics first. The first requirement was that we needed a discrete event simulation: one in which every action is simulated. While in the simulated world of The Matrix, in order to fool you into believing you are in real life, every object you touch, hear, and see, would need to be programmed: with its texture, sound and colour. The same way, we needed to replicate every interaction to fool our backend. For us, this meant mimicking with code every message-emitting hardware component, scanner, load carrier, and human operator that would interact with it.
For that, we focused on modelling three main components, two of which would have a direct interface with WCS:
- The Transport System (in direct communication with our Warehouse Control System)
- The operators performing actions (humans + screens, in direct communication with WCS)
- The hardware + PLC** logic (conveyor layout + robots + load carriers + stock) — not a direct interface
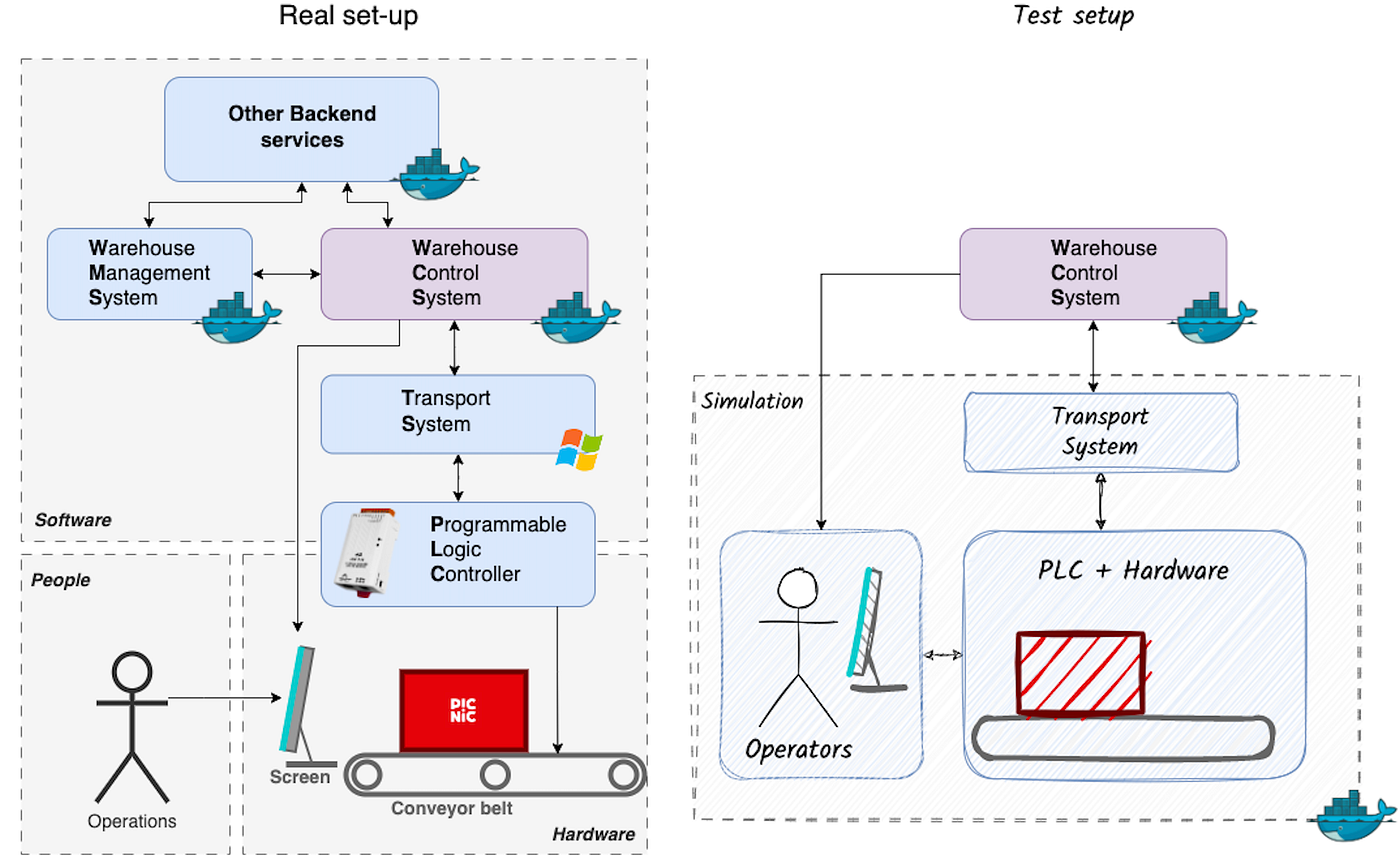
**Technical note: PLC stands for Programmable Logic Controller, whose role is to be the “nerves” of the hardware. They trigger every action such as “engage the conveyor at normal speed for 10 seconds”, “engage the diversion to the right for 4 seconds”. Our software, WCS, like the conscious mind, is in charge of the high-level instructions. The Transport System relays that instruction and the PLCs, like the nervous system, make sure these instructions are carried out.
Initially, we focused on accurately representing the direct interfaces: the Transport System and the Operators. The Hardware part was designed to make test-cases understandable: it reports where load carriers are in the simulation, what route they took, and why. To be as close to reality as possible, where WCS would run in a different environment than the other components, we isolated the simulation as well: it ran on its own Docker container.
Beyond the obvious
Making our simulation feel as real as possible was crucial. Our whole backend team -over a dozen developers- would use it as “the source of truth” for almost two years. Every bug costs double: a misrepresentation of reality in the simulation leads to a potential bug in the backend. Timeline-wise we could not afford much of these. Therefore, we took crucial but not-so-obvious design steps.
The first of these was to clearly split the implementation of our backend and the simulation. The day of go-live, WCS would communicate with a system written by a different team. Bothe are completely separate codebases. This made us decide to build the simulated TS in a different language than Java, the one we used for WCS. It provided a hard separation of concerns: no code could be shared between simulation and tested system. Otherwise, it would have been almost too tempting to borrow some API models from the WCS codebase into the simulation. We chose Python, a language we love at Picnic, and which we use -among many other things- to write component tests using behave for our software.
A different language also meant a separate simulation team: this -perhaps surprisingly- made things move. First, it brought us focus: our main responsibility was clear. We had to model the missing parts as best as we could, no other distractions. Secondly: it shielded our roadmap. Code that cannot be directly linked to “delivering new features”, even if crucial, is code that is in risk of being deprioritized. Especially in a tight-deadline environment as we were. As non-Java developers, all we could do to push for progress was to build an even better simulation, which was what the project needed.
Great, so we took neat design choices at the start. Did they work? Was this extra effort useful? Did we learn anything along the way? Let’s fast forward several months.

A clear common goal
Clarity was key. As seen in Part I, by operating in business features, the simulation made test cases understandable. For example: rather than testing our backend sent a list of correct messages in the right order, we checked whether a load carrier could successfully reach a picking station. This simplicity aligned everyone, enabling the whole team to work efficiently in parallel, as we all knew what to build:
- The product team specified the flows.
- The QA team used the specs to write high-level behavioural tests (the ones using the simulation).
- The simulation team built the components needed for the tests to run.
- Engineers built the WCS code as specified so that the tests passed.
Once each part was completed, the pieces would be put together and the features assessed as a whole. Bugs were easier to catch. Because the developers knew beforehand what needed to happen, root causes were less cryptic to identify and solve. All we had to do was to compare the expected route of the load carriers in the simulation warehouse against the actual one it took, and that would tell us the point where our backend made the wrong choice.
Complete features also meant thorough coverage. As several developers worked in parallel in different features, there was a high risk of these features not working as expected. Our simulation enabled the QA team -with a better high-level view of the project than engineers- to prepare exhaustive test cases that checked several parts working together. This helped us find many subtle issues that ensured our backend worked properly as a whole.
The simulation made us find bugs faster while we learned how our product behaved.
DevOps 101
The realistic deployment also prepared us for go-live. As the test cases represented authentic scenarios deployed in a reality-like environment, the dev team would use operational-like tools like log statements to do the debugging. That is precisely what we needed. In a DevOps philosophy, it prepared us -the dev team- for operations. The setup incentivized us to write helpful log statements right at the start of implementation, to help debug our tests later. Developing code to be efficiently run in operations.
The real-like setup also trained our operational eye. This exercise really paid off in commissioning and after go-live, where many unexpected events such as network issues, split brains, or faulty components demanded extensive debugging capabilities. It would have been significantly more difficult had we not practiced in those previous months with simpler versions of those issues we found in the tests.
But not every step was so smooth.
A hit of reality
The simulation worked well in the first months, as we built the happy-flow features, which assumed components worked as expected. For example:
- An apple is introduced into the warehouse.
- A consumer wants an apple, and that apple is picked at a station.
- An order is completed and successfully dispatched.

We navigated through these features steadily. Until we got to the unhappy-flow features. We had proved our system worked in optimal conditions, now came the time to make it failure resistant.
What if a piece of hardware failed? What if a sensor was mispositioned and could not scan the barcodes properly? These were not-so-infrequent scenarios, our system had to keep working! These scenarios put our simulation architecture to a real test: could it support unforeseen functionalities without too many changes? At this moment, reality hit us in the face: we had not gone far enough representing it.
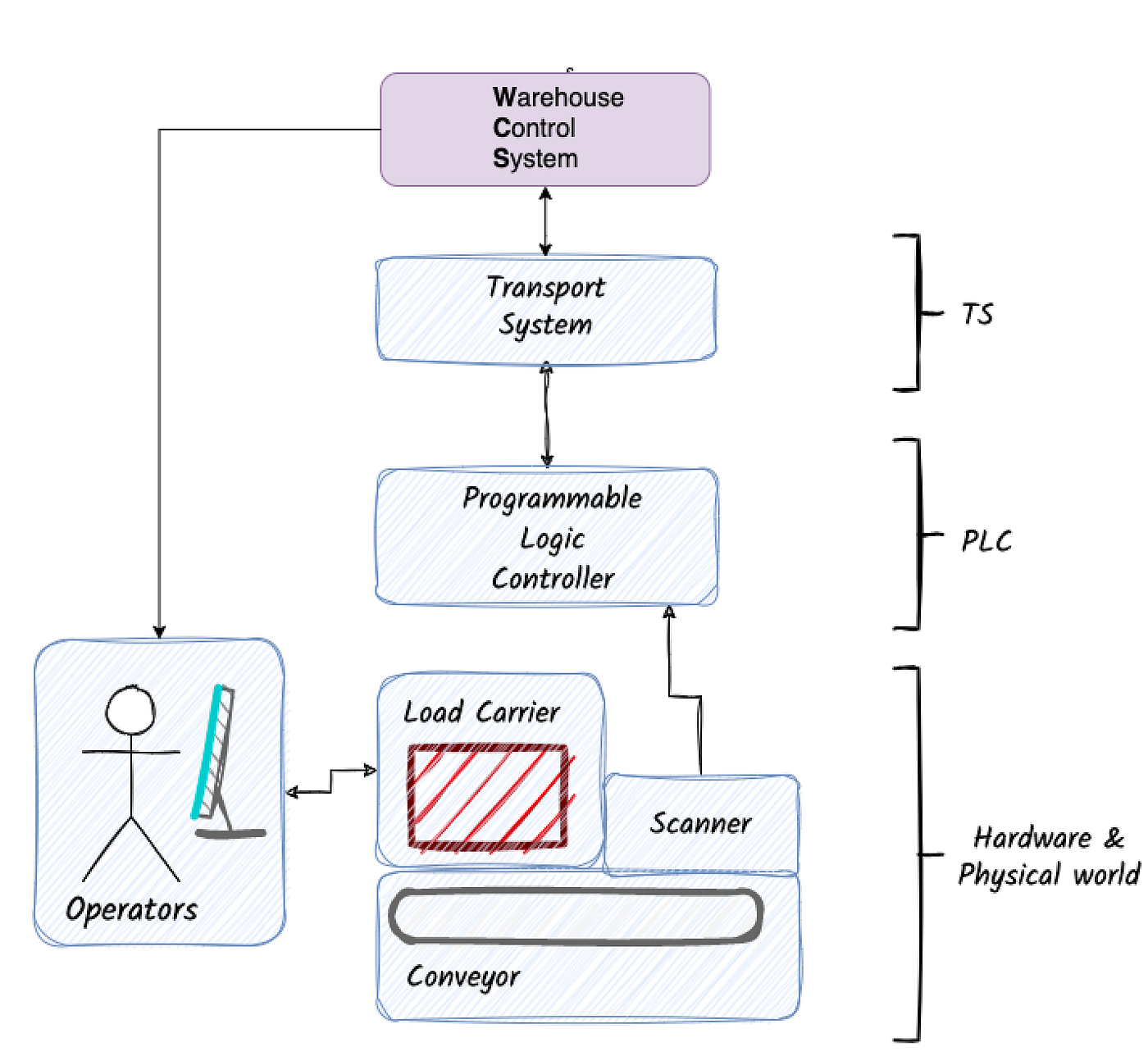
Our Hardware and PLC model was too simple. Initially, this was fine, as our backend did not directly interact with it. But now we needed to model more complex hardware failure scenarios. And for some of these use-cases, our simulation felt like a theatre piece with actors that are not good at improvising. Once the main character threw in a line too far from the script, the whole play collapsed. It was clear: we had not made a good enough logical split.
That is when a tough choice was presented to us. The tempting option of writing ugly and non-generalized code, or the pain of jumping into the rabbit hole of learning about the real interaction between these components -which, as software engineers, we knew very little of- and re-architecting the whole simulation code the proper way. Would we take the easy choice? The blue pill, or the red one? Like Neo in The Matrix, we chose the second: we would properly learn about it and model it as accurately as we could.
We suddenly became researches. Guided by Sjoerd, our Tech Lead, we went to the real site not to test our software, but to observe the hardware like zoologists studying a new species. We were lucky enough at the time that parts of the warehouse were being tested in preparation for the handover of the site to our team. We spent hours studying how components worked and interacted. We changed our mindset, and learned to see the world through the eyes of a PLC. It turned out to be a much more complex and fascinating world than we thought.

On close inspection, a working network of conveyor belts can almost feel magical. How can load carriers not collide with each other in intersections? What about when standing in line? How can the shuttle robots know where to pick up a load carrier to the precision of millimeters? All these questions we took for granted suddenly became really intriguing as we paid attention to them.
The answer was, of course: the PLCs. The mysteries of the hardware world became clearer to us. For example, we saw how light barrier scanners -small laser sensors triggering signals when objects pass through- placed along the conveyor networks allow the PLCs to know the position of a load carrier, so that it avoids collisions. Scanners also enable the PLCs to report information to the software layer, so that the latter one can decide whether the load carrier should be sent “left”, or “right”.
After our research, we came back to the drawing board, ready to model every component as it was in reality: scanners, light barriers, cables, conveyors, PLCs, PLC code, etc. We make the split right this time, every layer knowing the scope of its actual reality. This effort made our simulation a much more accurate representation of the real world, including edge cases. It also made us aware of a key unknown component of our system, the PLCs, without which our warehouse could not function. This effort also laid the first bricks of the future simulation team.
A look into the future
Automation is at the core of Picnic. We knew back then that more -and differently- automated warehouses were coming our way. We also knew the value of good simulations: key to deliver complete features and clearing as many risks as early as possible. We had a vision: to extend the use-cases of the simulation to do strategy simulations with thousands of load carriers. This would help us iterate over warehouse layouts in the early stages of design, with components almost like reality! That is why, even though our first automated warehouse went live, a brand-new Simulation team was born to fulfill all those use-cases, and build the complete new architecture we drafted.
Thank you for getting here! I would like to thank Sjoerd Cranen, Dylan Goldsborough, Marc Marschner and Sander Mak for reviewing Parts I and II. And especially, to the amazing people that brought Picnic’s first automated warehouse to life, and to those who continue to support operations so thousands of happy customers can get their groceries done by robots.
From now on, I will hand it over to Dylan, who in Part III of the series will dive deeper into the technical details -finally showing Python code!-, and will talk about another main hurdle we had to overcome: dealing with time. Hope to see you there!

