Picnic is a data-driven company. We rely on it for forecasting, fulfilling deliveries, doing analyses to support decision making, and this list goes on and on. Ultimately: we use data insights to make your grocery shopping experience the best we can! However, having to handle massive volumes of data can also bring up many challenges.
In this article, we will describe our approach regarding archiving data related to customer satisfaction, which is stored on our Customer Success solution.
“Wait… what do you mean by Customer Success?”
Oh, we haven’t introduced our Customer Success (CS) solution yet, have we? Well, let’s start from there.
It is powered by Salesforce Service Cloud and it focuses on Cases as an entry point. Each time a customer provides us with feedback via the app, tags us on social media, drops us a WhatsApp message or a phone call, a new Case is created. As a result, we have millions (yup, millions!) of them stored on Salesforce.
As part of our effort to provide a great customer support experience, we try to make sure the right agent handles the right Case at the right time. The process of matching cases to agents is called routing and doing it right is crucial for delivering success. With that in mind, we’ve built a skill matrix that retrieves, based on information such as the Case Origin, Language, or AAA Classification (we’ll get back to this later), the skills required to handle a specific Case. After the skill requirements are defined, each Case will be routed (using Salesforce’s skills-based routing model) to the most skilled agent.
We mentioned the AAA Classification field on the Case object. AAA stands for Advanced Analytics and Algorithms, and this field stores the value generated by feedback classification automations, which uses Natural Language Processing combined with machine learning to process customer feedback and suggests resolutions that help to reduce Customer Success response times.
Pretty neat, right? Do not forget to check the article by our AAA colleagues to get more insight into how these classifications are generated.
Data-wise it means that every time a new Case is created, additional records are created as part of Salesforce’s Omni-channel routing, such as Skill Requirements, Pending Service Routings, Agent Work, and Agent Work Skills.
Next to this, agents need to know what happened with previous customer interactions up to 3 years ago. These previous interactions will provide the necessary context for the agents to clearly understand the customer’s past CS experiences.
Picnic is also growing! And since with great business growth comes great data generation, that translates into a volume of Case and its related objects (Emails, Messages, etc) that gets bigger every day. In the long run, it can lead to poor application performance or scalability issues. And this is exactly what we want to prevent when the goal is to give CS agents a fast and smooth platform so they can focus on serving our customers well, right?
Finally, while working in the cloud has many advantages it also brings up some limitations. By employing a multi-tenant architecture, Salesforce enforces (not only, but also) data storage limits which we risk exceeding if we do not keep an eye on it. A fair amount of data generation versus limited data storage: you can already see where this is going, right?
It became clear that our main challenge would be to build an archiving mechanism so that we could stay within the Salesforce data limits while maintaining high levels of performance and data availability. So let’s go and find out what we can do!
To start with, we broke our challenge down into three key pieces
- Where to archive this data, data has to be deleted from Salesforce but as the CS Agents need the historical data to quickly identify previous interactions with customers we need to introduce a new middleware to store the most relevant objects;
- How to display it, since these records used to be visible on a standard Salesforce component but now we retrieve them from the middleware backend and present them to our end users (CS Agents);
- When to run the archiving process, as the daily operations shouldn’t be affected by it;
Where to archive this data:
To begin with, it is worth mentioning that the data we want to archive is already being captured by Picnic’s Data Warehouse (DWH). And at this moment you are probably thinking “Hang on, then why are you storing the same data in two places?”
Well, the reason is that different people need it for different reasons and in different manners.
DWH powers up analysts at Picnic to make data-driven decisions, but it isn’t suitable for operational purposes (as the data on DWH is stored and accessed via relations, and thus not so optimal for fast fetch requests). With that being said we decided to store this data also on another database (Mongo collections) so that agents can access it on the go.
This will be done with the help of our own Salesforce Bridge (a bridge between Salesforce and the rest of the Picnic ecosystem, consisting mostly of Java microservices), which will be acting as an intermediary between Salesforce and Mongo collections.
How to display it:
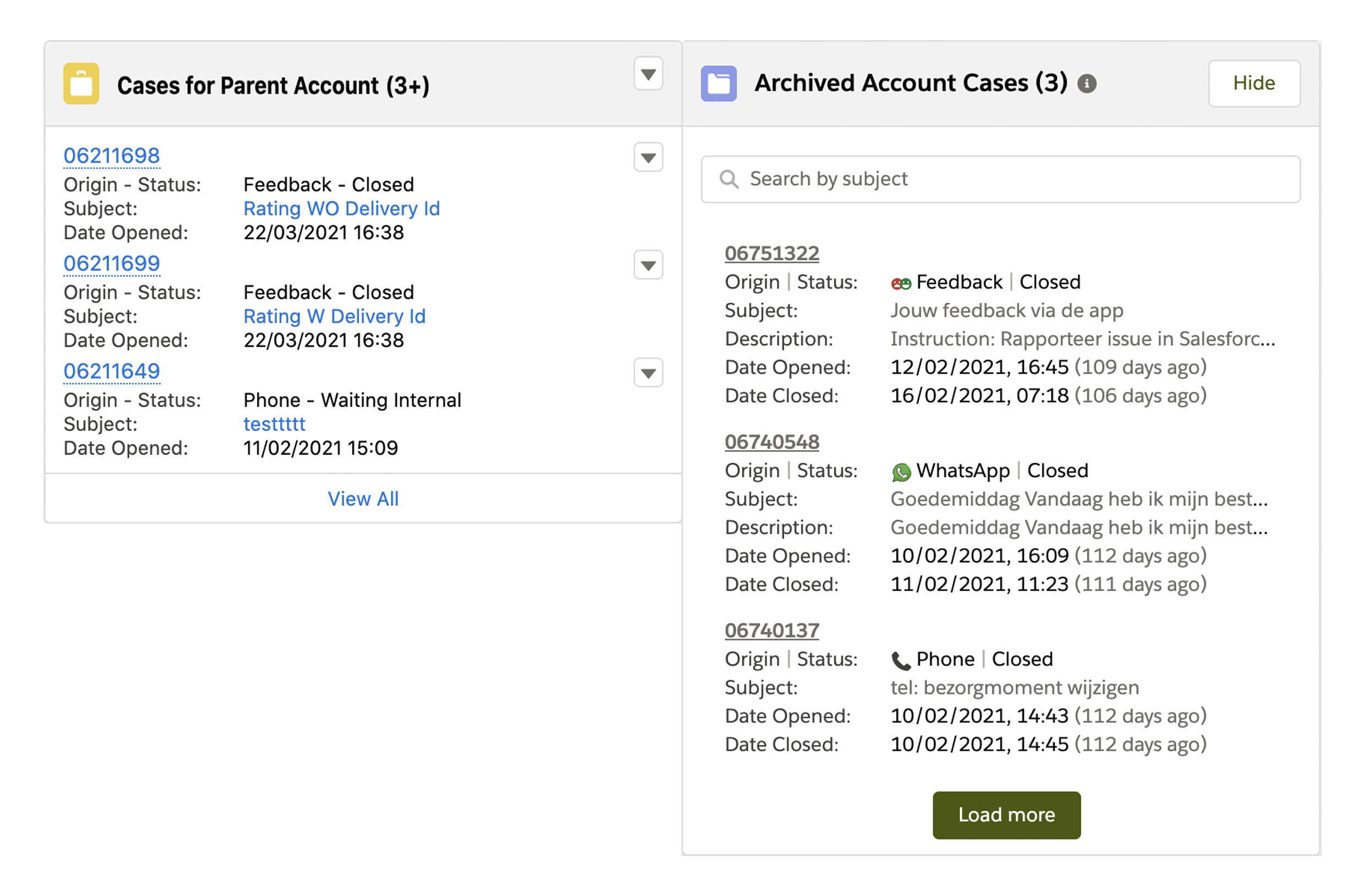
The team wanted to keep the look-and-feel of the standard Cases for Parent Account related list, so we decided to build our Lightning Web Component using Salesforce’s Card component (available on the Component Library) and style it using the Lightning Design System classes.
Since the component was custom built we tweaked it a little and included a search bar so agents could find the information they were looking for quickly without scrolling over all archived cases
This feature will provide quick access to all historical data, providing the agents with all context about the customer and allowing them to support the customer in the best way possible!
When to run the archiving process:
To make sure that our backlog doesn’t quickly grow we agreed on executing this process daily. The team also focused on keeping the daily operations running smoothly in parallel with the archiving mechanism, so our choice was to schedule it to run outside business hours (at 1 AM). That way, when the agents come to work in the morning the archivable records are no longer stored on Salesforce but are still accessible using the custom Archived Cases component.
We know what we want to archive, we know where we want to archive and we know when we want to archive. So let’s get started and build cool stuff!
The team started by developing a middleware backend to enable us to give the minimal set of data that agents need while keeping the data storage in place. That way we can archive data on collections and retrieve that same data in order to display it back to agents on Salesforce.
Before jumping into the actual development of the solution we would like to introduce yet another object which you will read about below: the Case Issue. In business terms, it represents an occurrence related to a customer, a delivery, or a specific article, but you can think of it as a Salesforce Custom Object which may or may not be related to a Case through a Lookup relationship.
Alright, the development!
We began with the backend process to collect and send the records which were identified by business rules as being ready to be archived (meaning Cases that have been closed more than 90 days ago, alongside their respective Case Issue records) to the Salesforce Bridge.
To fulfill this requirement we have implemented two batchable classes:
- One where the scope will be Case Issues (which are not related to any Case), where we will invoke the endpoint to archive them and afterward delete them from Salesforce.
- One where the scope will be Cases. Here, on each execution, we will archive both Cases and their related Case Issues. If both archiving requests return a success status code then we’ll be ready to delete this data from Salesforce.
On both operations, we always wait for the endpoint to return a response status before deleting the records from Salesforce. That way we can ensure that data deletion only occurs if the archival process was successful.
A Custom Metadata Type was created to store the batchable size for each object to archive (this way we can easily scale it to different objects with different limits) and the number of records to send to the endpoint on each execution since there is also a maximum batch size defined on the Salesforce Bridge.
That way, if we want to increase or decrease the number of daily records to archive, all that’s needed is to change the metadata record, and… that’s it!
How to test it?
After the batch, developments came the Apex tests, and here we faced a small challenge while trying to generate test data. Due to the fact that our queries focus on the Case ClosedDate, and this field is not writeable, we needed to have valid test data records or mock implementations of these records. After taking a couple of approaches into consideration we decided to go with dependency stubbing and use FFLib’s ApexMocks Framework which we were already using in our environments. That way we can avoid those not-so-elegant Test.isRunningTest() statements and focus on testing our code’s logic.
One-off migration:
More than 3 million cases and 2 million case issues were identified before the release as archivable.
Let’s say we used the default batch size (200 records per batch scope) a total number of 15.000 executions would be performed (fun fact: if we decided to run batch with 1 record per batch scope, and assuming that each execution would take around 20 seconds, our migration would be finished after almost two years!).
Bottom line? We needed to come up with a solution to clean the majority of them until our scheduled processes were assembled.
With that in mind, an initial extraction was made for records that could be archived up to three days before the release, and directly inserted into Mongo collectionsand deleted from Salesforce with the help of the Bulk API, which allows us to optimally load or delete large sets of data. Then the remaining set of records, which would be much smaller than the original scope of records could be archived by the scheduled batches and everything would be in the right place.
GDPR compliance
Let’s not forget that all data we’re mentioning in the article is related to individual customers, and with GDPR rules came the “right to be forgotten”. That was also taken into consideration: if an individual request for their data to be anonymized a UserService eventis triggered, ensuring we do all the required actions to forget the customer.
From that point on the process follows two streams:
- The event will be received by Salesforce Bridge, which will be responsible for deleting the archived Cases / Case Issues data stored on Mongo related to the customer.
- The data masking is propagated to Salesforce itself (as a consequence changes will subsequently be propagated to DWH). This data is anonymized on Salesforce/DWH as it is still useful for analysis.
Summing it up
Taking our German Salesforce environment as an example: we were using around 120% of the allowed data storage before this archiving process took place. After the initial archiving process took place this percentage lowered to around 75%, which clearly indicates our efforts paid off!
and still access migrated data on a similar UI/UX experience
With the archiving process rolled out and the batches scheduled we will save storage, maintain our performance levels, and still have all the data available for both Customer Success Agents (stored on the Mongo collections and accessible through the Salesforce Bridge), and for analysts (accessible through DWH), so everyone that needs the data can get it!
Future work
Our plans for the future include the expansion of the archiving process for additional objects (remember the records related to the Case which we mentioned at the beginning of the article? Exactly, we’re looking at those!), improvements on our component to provide supplementary detail to the agents and much much more!
Did you find these developments interesting? Then you will definitely enjoy all the other fresh and challenging tasks we’re tackling on Salesforce, such as automatically rerouting work that would otherwise not be routed by Omni or building complex integrations with either internal or third party services.
Oh, and did I mention we are doing this while implementing a robust CI/CD process on top of a multi-org architecture using Salesforce’s Package Development Model?
If you would like to be a part of the team and work on these activities and many more, please take a look at our job opportunities!



 Erdem Erbas
Erdem Erbas