Forecasting at Picnic
Picnic is proud to deliver groceries to our customer’s doorstep in a sustainable manner and with great service. Using data science, we keep our customers happy and at the same time prevent food waste. The ability to predict customer demand accurately is a critical factor in reducing waste and ensuring customer satisfaction. At Picnic, we track the latest machine learning developments to ensure the best possible demand forecasting. This blog post delves into the learnings and challenges on our journey towards implementing and scaling state-of-the-art deep learning approaches. We’ll shed light on how to use the newest machine-learning approaches in a controlled and reliable manner.
Article Demand Forecasting
Our goal is to predict what articles will be ordered by our customers in the future, so we in turn can order the right amounts at the right time, automatically purchasing groceries from our suppliers at scale. Accurate demand forecasting is also vital for minimizing waste and avoiding product unavailability.
For individual products and warehouses, the process might seem straightforward. You could use simple machine learning models and packages such as ARIMA, XGBoost regression or FBProphet. In some instances, calculating a moving average with SQL queries or leveraging already-known demand for products ordered by our customers will be good enough. A good example of a product where we often already know how much we need to bake in the morning is bread, which is ordered by our customers the day before. For that use case a simple SQL query can be enough. But for knowing how much dough is required to bake that bread we need to look further ahead and machine learning is a useful tool.
A core piece of advice I would give anybody working with forecasting or any type of machine learning: start very, very simple. This helps with understanding the problem and gives you something to fall back on. But what if that simple approach fails to fully resolve a complex problem? Then, it is time for the next big step.
Using Deep Learning Models
At Picnic, our commitment to reducing food waste and keeping customers happy takes the task of demand forecasting to the next level. We productionize deep learning models like Temporal Fusion Transformers (TFT) and evaluate new models such as Tide, and TSmixer. We even look into multimodal approaches to demand forecasting as can be read in this blogpost. After revolutionizing the world of language processing and computer vision, transformer-based models are also the best in class for many forecasting challenges. These models thrive on handling a plethora of input features — from product details and holiday periods to weather predictions, promotional activities, and our unique recipes. The rich context provided by our Snowflake-powered Data Warehouse enhances their performance, allowing us to create a robust feature set for training. When you have highly detailed, timely, and high-quality data as we do at Picnic, it becomes relatively easy to run benchmarks for your forecasting problem to determine if using the newest techniques adds value.
Training these models on our historical demand and assessing their performance is manageable as a one-time project since concepts like data drift are still not a big concern. Later we will dive into what is more challenging: continuously training and improving deep learning models in a controlled manner.
Maintaining Data Quality
Anybody working with machine learning knows the saying “Garbage in, Garbage out” because of one reason: it is true. When putting bad-quality data into machine learning models, you will get bad-quality output. Maintaining data quality throughout the pipeline is crucial, even with high-quality data sources like the ones at Picnic. The effectiveness of machine learning models is directly tied to data quality, as poor data quality inevitably leads to unreliable predictions.
One of the measures we take to make sure our models are always as good as they can be involves regular retraining of models to address data drift, concept drift, and the introduction of new articles and warehouses. While simple SQL queries don’t require retraining, sophisticated models like TFT do, demanding considerable computational resources. Thankfully, our GPU-enabled infrastructure facilitates frequent, automated model retraining, allowing our team to focus on system enhancements rather than manual model training. Due to the available infrastructure training models that require a lot of computing at set intervals is as easy as scheduling a cronjob.
We can only trust our machine learning models to ‘train themselves’ because of rigorous validation at every step of a data point’s life cycle. Whenever the model is trained we compare evaluation metrics over a variety of subsets with other models in our model tracker to see if they are indeed more performant. When the newer model is successfully improved it will automatically be deployed and will be used at a moment’s notice to create predictions used by our operations.
But machine learning models can also start misbehaving even after automated and carefully crafted evaluations. For this reason, we log all our predictions in a standardized manner, allowing for subsequent evaluation by our analysts. These analyses, combined with automated tools like our in-house model performance monitoring package, allow us to execute detailed checks on the models for errors. In turn, this means we can continuously improve our models. Comprehensive monitoring ensures that even as we rest, our machine-learning models are under constant surveillance.
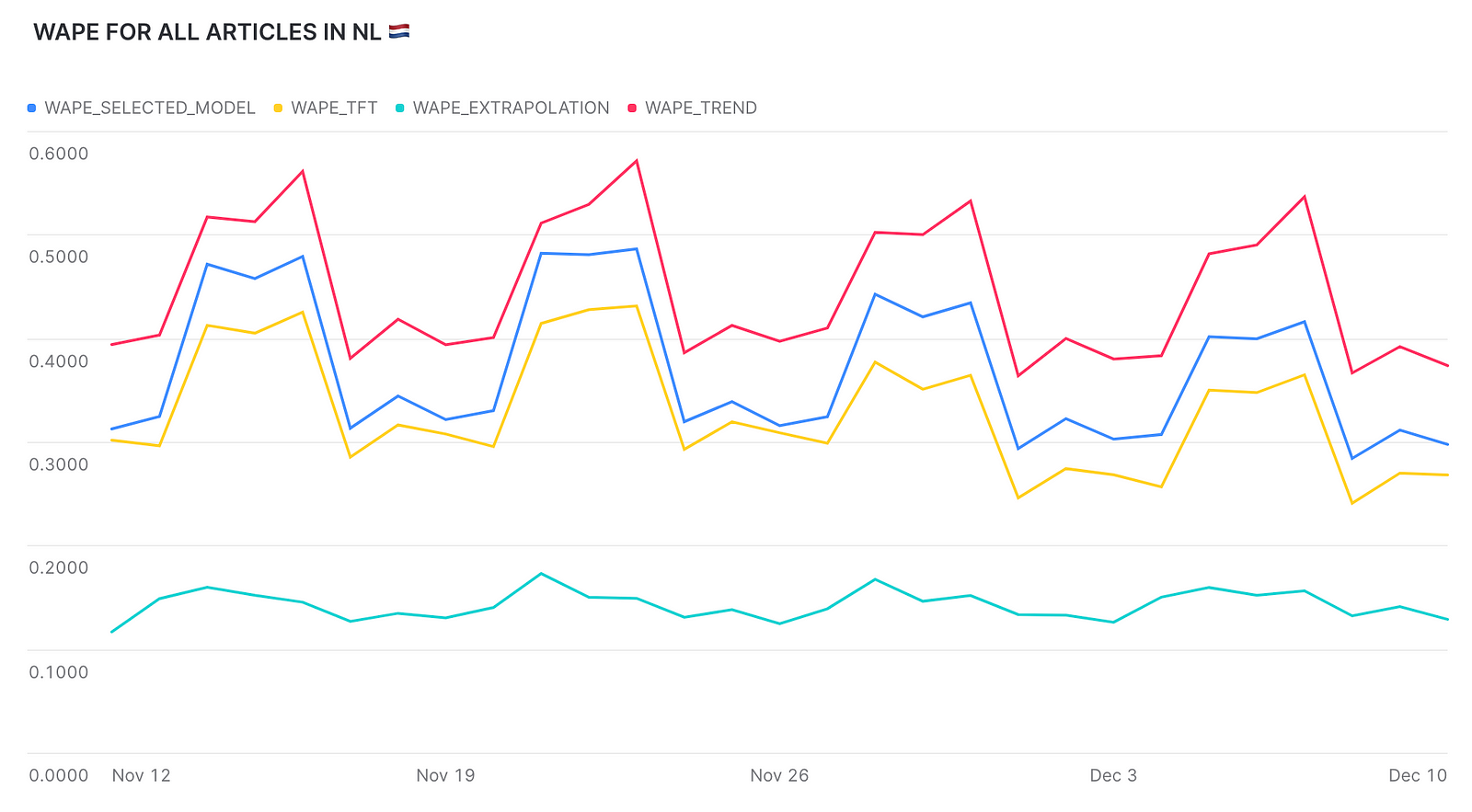
Outlier Detection
“pandera is an open source project that provides a flexible and expressive API for performing data validation on dataframe-like objects to make data processing pipelines more readable and robust.” — https://pandera.readthedocs.io/en/stable/
We use Pandera to ensure data integrity and flag outliers in our machine-learning pipeline. For example: Any prediction deemed potentially inaccurate based on a validation schema will not be used in our operational processes and we fall back to the latest known accurate predictions. Meanwhile, we can look into the problem and do root cause analysis without the issue having an immediate operational impact. Recognizing and addressing the inevitability of errors in machine learning, much like human error, is not just about prevention but also effective management and resolution. Pandera allows us to quickly take samples of our tables and validate them. Below is a snippet of code of how a simple check looks for sensical weather information. Checks like this are easy to integrate into existing pipelines, and has saved us many times already. We integrated the validations frequently our training pipeline, inference pipeline and as mentioned also on our predictions.
"1" data-code-block-lang="python">import pandera as pa
# Pandera allows for the creation of validation schema's.
weather_features_validation_schema = pa.DataFrameSchema(
columns={
"avg_cloud_cover": Column(checks=Check.in_range(0, 1), nullable=False),
"min_temperature": Column(checks=Check.in_range(-30, 50), nullable=False),
"max_temperature": Column(checks=Check.in_range(-10, 60), nullable=False),
"avg_wind_speed": Column(checks=Check.in_range(0, 20), nullable=False),
},
unique=["key_delivery_date","key_fc"],
)
# Since the datasets can be big, we take a small representable sample which is validated.
sampled_dataframe = sample_snowflake_table(table_name, num_rows_sample)
# Pandera will use the validation schema to log insightfull errors when a check if triggered.
weather_features_validation_schema.validate(sampled_dataframe)
Scaling up
The article demand forecasting challenge intensifies when deploying multiple models simultaneously in a production environment. We’re making hundreds of millions of predictions a day for a vast array of articles and warehouses with multiple machine-learning models. As we’re selling tens of thousands of products across various countries, Picnic requires a machine-learning software stack that is not only robust but also scalable and operating with low latency.
Building upon our extensive experience in developing scalable software solutions — from customer-facing apps to precision-driven warehouse systems — the machine-learning experts collaborated with seasoned software engineers within Picnic to design a machine-learning architecture capable of handling an even greater volume of predictions. This led to a scalable system for pre-computing and swiftly delivering predictions to our purchase order management system. The new scalable system has capabilities that allow for scaling up resources when under high load and is designed in a way that there are no bottlenecks for scaling Picnic up even further.
But most importantly we pre-compute all possible predictions that can be requested frequently instead of doing it on the fly. This might seem less efficient, but when measuring it turns out to be more robust and even more efficient than only calculating predictions when requested. The reason for this is that Machine learning packages are often very good at calculating batches efficiently, but are not very efficient at doing a lot of small batches of predictions. Pre-computing all predictions also gives the added benefit of having fallbacks by design, your models breaking in production no longer mean an incident with an immediate critical impact on Picnic’s operations. It is always better to have slightly older predictions than have faulty predictions or no predictions at all!
Wrapping up
What can you take away from Picnic’s journey into running demand forecasting models at scale? Here are a few lessons we learned:
1) Believe in machine learning models to make your business more efficient, but make sure that your software handles mistakes that will be made by machine learning (because it will) appropriately.
2) Use software engineering approaches to scale machine learning. While a lot of machine learning models are new, software engineering is not.
3) Even though your data is of high quality, the world can change. Be sure to constantly evaluate predictions made by machine learning models, both when they are created and afterward. Both with automated systems/processes and by human expert analysis.
4) Old predictions are better than incorrect predictions. It is better to fall back to a cached value and alarm you than to use potentially incorrect predictions that have real-world impact.
And of course: start simple whenever considering utilizing machine learning, you will need a baseline and a fallback anyway.
Hope the learnings in this blog post are useful when you are working on bringing models to production, or when upgrading your systems to scale up for a growing supply chain. Machine learning really is a great ‘new’ player in the world, and deep learning allows operating at the Champions League level. You just need to make sure you take into account the unexpected, as patterns from the past are certain to not always be a pattern of the future.



 Janneploeger
Janneploeger