

A little over a year ago, we shared a blog post about our journey to enhance customers’ meal planning experience with personalized recipe recommendations.
We discussed the challenge of finding culinary inspiration when personal preferences aren’t fully considered — like encountering that one veggie you’d rather avoid. We explained how a system that learns from your tastes and habits could solve this issue, ultimately making the daily task of choosing meals both effortless and inspiring. After all, everyone needs to have dinner every day, so why not make daily meal planning as enjoyable and efficient as possible?
Building on that vision, we’ve continued to refine our approach. In this post, we’re excited to take you behind the scenes once again, diving into the technical advancements that have taken our system to the next level. We’ll discuss how we addressed the limitations and challenges of our initial collaborative filtering approach, and tackled the complexities of integrating recipe and customer attributes using more sophisticated techniques.
You’ll learn about the foundational concepts that drive our new system, including how we reframed the problem, the new challenges that came with it, but also the benefits it unlocked. Ready to see what’s new? Let’s get started.
Overcoming limitations
Building a machine learning system starts with translating a real-world problem into a well-defined task. This requires answering key conceptual questions: What’s the learning objective? Is it supervised or unsupervised? Should it be framed as classification, regression, or perhaps reinforcement learning? What’s the target variable, and how should the model represent it?
In recommender systems, these choices aren’t always straightforward. “Personalization” can take many forms, each with trade-offs, and the best approach depends on context and constraints. There’s no universal solution — defining the problem and its assumptions is a core part of the ML engineering craft.
In our previous blog post, we explained how we approached the problem by leveraging collaborative filtering — a technique that uses user-item interaction data to shape a matrix for similarity calculations and top-item recommendations. This method proved surprisingly effective for customers with extensive interaction histories. However, as we explored further, several limitations became apparent.
The approach struggled with scalability, making it difficult to handle large datasets efficiently. It also suffered from the cold start problem, offering little support for recommending new recipes or helping new customers. Over time, we noticed that recommendations tended to repeat, reducing diversity, and freshness.
Moreover, collaborative filtering’s reliance solely on interaction data limited our flexibility in feature engineering. This kept us from leveraging valuable information about recipes and customer preferences, making it less adaptable to the specific needs of our customers. These challenges underscored the need for a recommendation system that could better adapt to our data and user needs.
Incorporating content characteristics is widely recognized as a strategy for improving generalization and overcoming cold-start issues. Neural networks, particularly the two-tower architecture, offer an effective approach for content integration and keep gaining attention. They learn not just from user-item interactions, but also from user and item attributes, along with contextual factors. Despite the added complexity, we chose to implement this approach. Let’s take a closer look at how we did it.
Reframing the problem
Adopting the two-tower model forced us to rethink our problem formulation, shifting from an unsupervised method based on interaction matrices to a more flexible framework. As depicted in Figure 1, in this new formulation, interactions are treated as independent data points, each enriched with contextual information. This includes details such as the timing of the interaction, the customer’s preferences at that moment, and the recipes’ category.
In practical terms, this means we now work with a tabular dataset of interactions instead of a matrix.
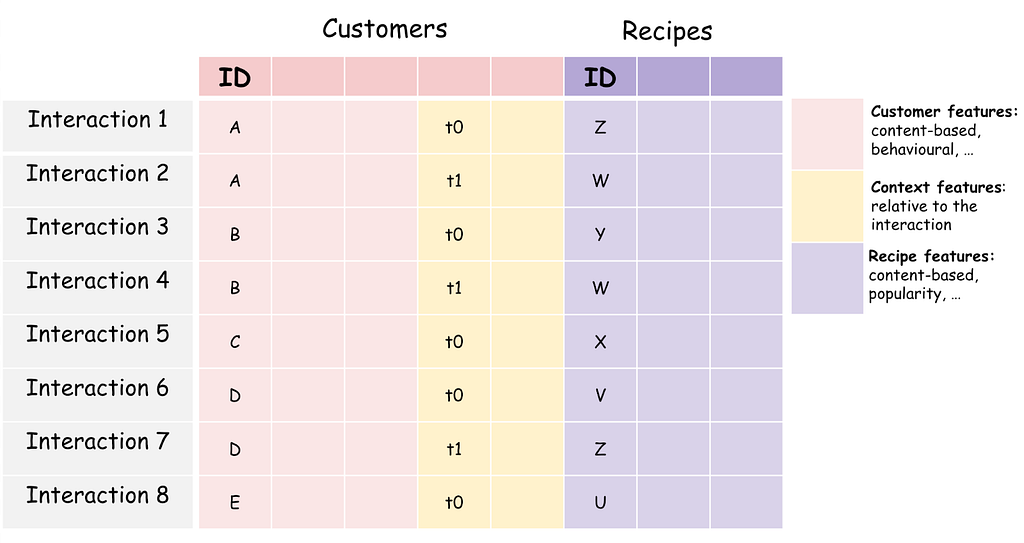
Figure 1: A stylized representation of a tabular dataset of interactions in the use case of a recipe recommendation system.
Now, we are no longer confined to using only aggregated past interactions, such as how many times a customer has engaged with a recipe. Instead, for each customer-recipe interaction, we can now include detailed information about the customer’s preferences at the time of the interaction. This includes their dietary preferences, whether they are vegan, or if they favor quick recipes, among other features derived from their buying patterns.
Additionally, for each interaction, we can specify the characteristics of the recipes, such as their type, cuisine, primary proteins, and cooking time. But it doesn’t stop there. Under the umbrella of customer features, we can also capture the context of each interaction, including the time of the interaction, whether it was a weekend, the weather conditions when the customer placed an order, and even real-time data like recent searches or app interactions leading up to the order.
Conceptually speaking we can now see how this new problem formulation allows us to create a much richer dataset, and hence build a much more nuanced and generalizable model. However, coming back to the initial question of how to frame the ML task, what type of task are we talking about now?
The machine learning task
Before answering this question, let’s first establish the foundation of typical recommendation problems. In recommender systems, the terms queries and candidates describe recommendation problems, where each query is linked to one or more relevant candidates from a larger corpus. These connections form a dataset of interactions.
But what exactly counts as an interaction? An interaction is any user action that provides insight into their preferences. These interactions typically fall into two categories: implicit feedback, such as clicks, views, and purchases, and explicit feedback, like star ratings or written reviews. Some systems have access to both types in large quantities and can combine them to improve accuracy, while others may rely primarily on one. In this Picnic use case, we focus on implicit feedback, using it to construct a dataset of positive interactions. Each row represents a positive event — such as a customer purchasing a recipe — along with relevant content and contextual information.
That said, how can we best leverage this data in a modeling approach to build a recommendation system? The two-tower neural network architecture is one commonly used modeling technique in this space. It works by separately encoding query and context features in one tower and candidate features in another. These two representations are merged at the top using a lightweight scoring function that captures their interaction.
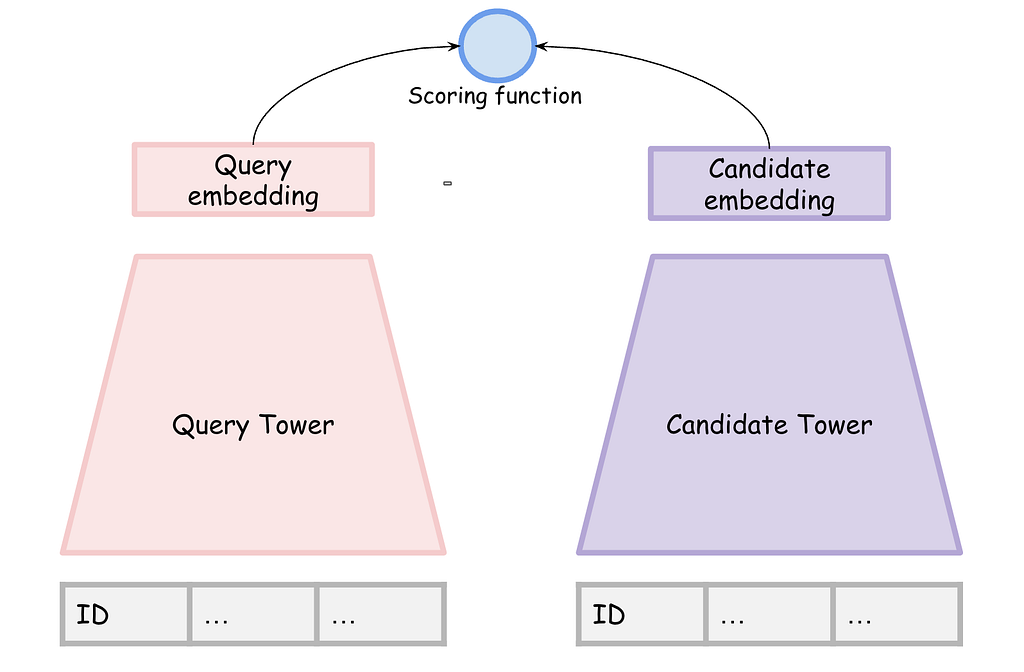
Figure 2: A stylized representation of the two-tower architecture.
This architecture is particularly valuable because it supports the two most commonly used learning tasks in recommendation problems: retrieval and ranking. It allows models to handle either or both tasks using implicit or explicit feedback, making it highly adaptable to various recommendation scenarios.
The choice between ranking and retrieval, as well as the type of feedback to use, depends on multiple factors, including the type and quality of the available feedback and the business goals.
For example, in scenarios where explicit feedback is abundant — such as user ratings — ranking naturally aligns with the problem structure. Since ratings provide clear labels, ranking can be framed as a supervised learning task, either as classification (if feedback is binary) or regression (if ratings fall on a continuous scale).
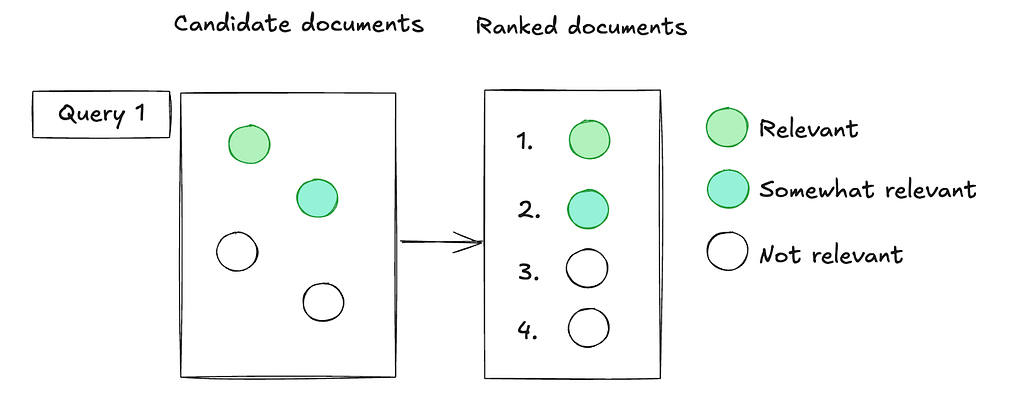
Figure 3: A stylized representation of a ranking problem.
When implicit interactions (such as purchases) are the primary signals available, and the goal is to surface a shortlist of items a user is likely to engage with, retrieval becomes a natural approach. A retrieval model helps efficiently identify relevant candidates, which can then be further refined depending on the specific needs of the recommendation system.
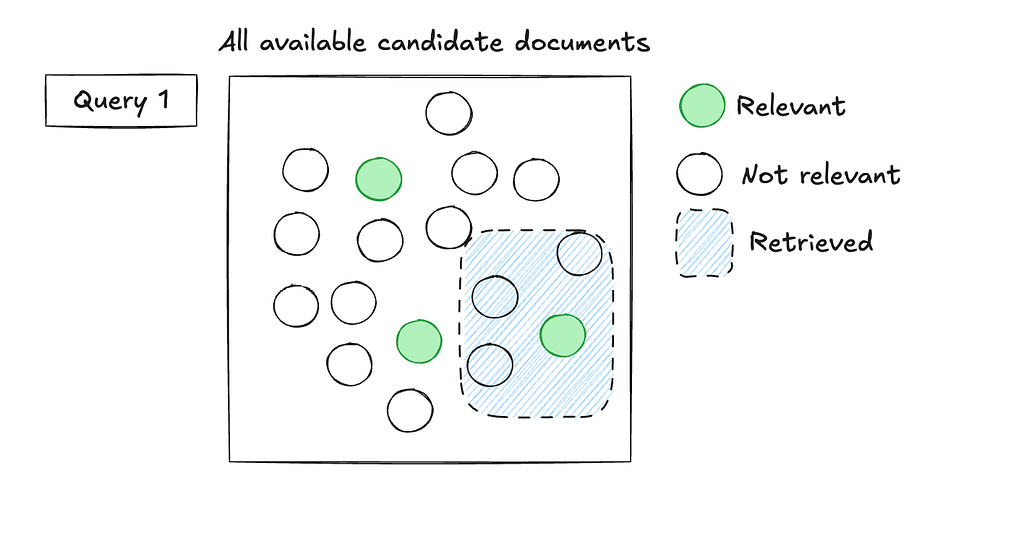
Figure 4: A stylized representation of a retrieval problem.
Candidate corpus size also matters. For large sets (over a million), both are needed and retrieval comes before ranking. With smaller corpora, either a ranking or retrieval model — using implicit, explicit, or both types of feedback — may suffice.
Applying these principles to our use case at Picnic, we trained a retrieval model using the interactions dataset described in the previous section. This approach best aligns with our data and business needs, ensuring we generate a focused set of recommendations tailored to Picnic customers.
Handling the Lack of Negative Interactions
A key challenge in training retrieval models with implicit feedback is the absence of explicit negative interactions. Unlike explicit feedback systems, where users can directly indicate dislike for an item, implicit feedback lacks true negatives. This raises an important question: How does the model learn to distinguish between items a user is likely to interact with and those they are not?
The answer lies in negative sampling — the process of selecting negative interactions during training. A common approach is to treat any unpurchased or unclicked item as a negative, assuming that if a user didn’t interact with an item, they aren’t interested in it.
In this project, we used TensorFlow Recommenders (TFRS), which implements this negative sampling strategy automatically. Specifically, the retrieval model attempts to maximize the similarity between queries and candidates that interacted with each other while reducing the similarity between queries and candidates that didn’t.
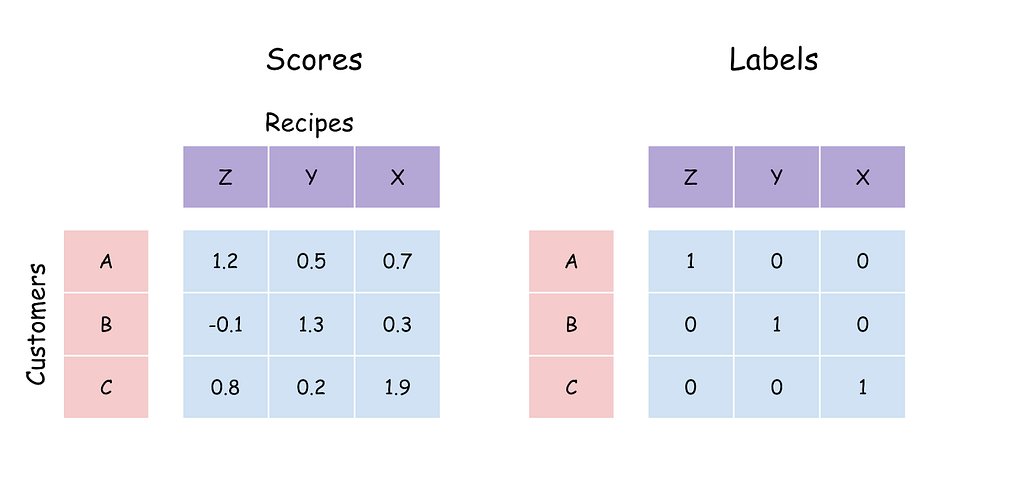
Figure 4: A stylized representation of how negative samples are generated during training in TensorFlow Recommenders to compute the loss.
Here’s how it works in practice: for each training batch, the model computes the dot product between all query and candidate embeddings, forming an n × n similarity matrix. It then constructs a second matrix — an identity matrix — where interactions that actually occurred are marked as 1, and all others as 0. These matrices are used to compute the Categorical Crossentropy loss, effectively treating all non-interacted items in the batch as negatives. Figure 4 provides a visual representation of this process.
This approach streamlines negative sampling, but it also comes with two fundamental challenges.
First, it suffers from popularity bias. In nearly every recommender system problem, interactions follow a long-tail distribution: a few popular items dominate and many others appear infrequently. Because popular items appear more frequently, they are more likely to be sampled as negatives in any given batch, biasing the model’s learning. Second, it relies on the assumption that all non-interacted items are negatives, which isn’t always true — a user might have simply never seen the item, or it may not have been recommended at the right time.
Both of these challenges stem from treating negative sampling as a uniform process, when in reality, user behavior is much more nuanced. Luckily, TensorFlow Recommenders allows adjusting the probability of a candidate being sampled as a negative based on its frequency in interactions, which helps smooth the popularity bias effect. However, there are more sophisticated techniques that go a step beyond and sample negatives based on item characteristics. They focus on items that are meaningfully different from those the user has engaged with. Yet, overdoing this can reinforce biases and create filter bubbles. A balanced approach ensures the model captures preferences without restricting exposure to new content.
Wrapping Up
At the start of this blog post, we outlined the limitations of traditional collaborative filtering — cold-start issues, lack of diversity in recommendations, limited feature engineering, and scalability challenges. To overcome these, we explored a new approach: structuring the problem as a tabular dataset of implicit positive interactions and building a retrieval model using a two-tower architecture.
Now, our two-tower model learns from millions of interactions while seamlessly incorporating rich contextual features ranging from the weather conditions to whether a customer owns an oven or not. Unlike the previous method, it can generate relevant recommendations for any customer, even those who have never interacted with a recipe before.
By reframing our recommendation problem, we’ve built a system that not only solves cold-start challenges but also ensures more nuanced and dynamic recommendations — resulting in a smoother, more intuitive, and engaging customer experience.
Of course, our journey doesn’t end here — building the model is only one piece of the puzzle. Bringing it to production introduces a whole new set of exciting challenges. As we continue to iterate and scale, we’re tackling questions around deployment, integration, and real-time performance to ensure the system is as responsive and effective as possible.
Stay tuned as we continue evolving the system and overcoming new hurdles. We’d also love to hear your thoughts! If you have ideas or experiences building recommender systems, feel free to share them with us.
Solving the weekly menu puzzle pt.2: recommendations at Picnic was originally published in Picnic Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.

