

Introduction
Transformer models have revolutionized natural language processing with their human-like text generation capabilities. At Picnic, we’re using these models for demand forecasting to minimize waste, increase customer satisfaction, and support sustainability. We even experimented with using transformers and neural networks to help demand forecasting models to understand our products better. Want to learn more about why and how we aim to do that utilizing fruit and festive experiments? Then you are in the right place!
In this blog post, we’ll discuss how we teach transformers to distinguish between products like a potato and a banana, thereby enhancing future demand prediction. And yes, we might get a bit technical. But whenever it becomes too technical make sure to scroll down toward the conclusion where we wrap it up for humans again.
Article Demand Forecasting serves as the foundation of any efficient supply chain, particularly when bringing fresh products to customers as Picnic often does, where the difference between surplus and shortage can often boil down to hours. An always though example is predicting how much Fruit will be ordered for the next day because we already need to order enough before our customers order it. Order too much? We will have a surplus of fruit. What happens when we order too little? Our customers that are doing a good job trying to eat healthily might not be able to order their favorite healthy snack! Accurate Article Demand Forecasting makes our customers happy whilst reducing waste and increasing sustainability.
Challenges in Traditional Demand Forecasting
Traditional ways of predicting product demand are based on past sales data, seasonal patterns, events, and broad product categories. While these methods can be useful, they often struggle with certain problems. For example, they might not capture the full picture of how individual products within a category are doing. In online stores, small changes in product variety or how products are shown can hugely influence what customers buy. Also, traditional methods struggle when a product is new and doesn’t have any sales history.
Given these challenges, a smarter way to predict product demand is needed. Online shops change quickly, and old methods can’t keep up. However, newer techniques using advanced machine learning can help. These techniques don’t just rely on past data but also learn from similar products’ features collected from images and texts. This shift towards a more intelligent, feature-based approach offers a promising future for demand prediction. It’s also exciting to see that research in machine learning is looking at how more advanced methods, such as deep learning and transformers, can be used for even better demand forecasting.
The Power of Transformers
GPT, or Generative Pretrained Transformer models, are well-known for creating highly realistic text. As fascinating as this ability is, we should question if this is the most critical use of this advanced technology, especially considering its high computational demands and the environmental concerns they raise.
Transformer models, however, are not only about text generation. They offer a wide range of applications across different fields. For example, Temporal Fusion Transformers (TFTs) are top-notch tools for predicting product demand, proving more accurate and reliable than older models. They can also turn texts and images into meaningful product descriptions, expanding their use. By converting raw data into valuable information, transformer models could significantly contribute to sustainability. They could help create a future with less waste and more effective use of resources. While generating text is impressive, these wider applications of transformer models might make the most meaningful difference.
Our approach
Our hypothesis is that combining visual and textual features will capture the product’s essence more effectively, thereby boosting the Temporal Fusion Transformer’s demand forecasting performance. That is why we explored the usage of Multimodal Temporal Fusion Transformers, a pipeline capable of understanding the characteristics of our products, and are thus better at predicting demand than more ‘traditional’ state-of-the-art approaches for demand forecasting.
Textual data

Product textual features — including descriptions, names, and ingredients — harbor insightful details about the product. Consider a product with “BBQ” in its description, which is more likely to see demand on holidays and warm days. Similarly, certifications for salmon could impact its sales in regions where sustainability is prioritized over price.
For extracting such textual information, we utilize the compact yet effective DistilBERT architecture, renowned for handling multilingual sources. We enhance this pre-trained model by appending a final layer with reduced dimensionality, facilitating integration with the Temporal Fusion Transformer. The model is trained to predict average article demand, using textual features including product name, ingredients, and description. A linear layer is added to the final layer of DistilBERT, condensing the dimensionality of textual features to 10. This is due to the fact that when training a TFT on a large quantity of data as we do at Picnic, it is important to keep the size of the train features reasonable.
In the future, we will also experiment with using Large Language Models like GPT-4 or the last week’s released LLaMA 2. Expectations are that that will work even better, but as our shoppers know it is always important to first start walking before you start running: it is safer like that!
Visual Data
The images of Picnic’s beautiful products are essential for our customers to decide what they buy, so using them must be essential for predicting article demand, right?

To evaluate the utility of visual features in demand forecasting, we’ve fine-tuned the ResNet152 architecture, which is pre-trained on ImageNet, for this task. Product images undergo preprocessing, which includes squaring via padding and resizing to 224×224 pixels. We enhance dataset diversity by applying random horizontal flips and rotations. Subsequently, images are normalized to match the pre-trained weights in ImageNet. The final layers of the ResNet are reconfigured to produce linear output, and the model is trained using Mean Squared Error Loss on the Average Product Demand. To ensure compatibility with the Temporal Fusion Transformer (TFT), the visual embedding’s dimensionality is reduced to 10 through the addition of a linear layer to the ResNet architecture. And there are many more advanced computer vision models we could use: but if Thor would always use the most advanced tool, would Thor really be Thor?
But of course that does not mean there are no other tools, we also experimented with using BLIP an approach that can be used for texts and visual input, or even a combination of both. For visual data, this performed better than the finetuned ResNeT approach which is impressive! Thus: for anybody looking for a quick way to create visual embeddings (and even textual and multimodal), we can recommend BLIP from Salesforce. This method is very effective for most tasks and does not require a lot of finetuning.
Caption: Like Thor, you need to use the right tool for the job, not the newest.
Putting it all together with Temporal Fusion Transformers
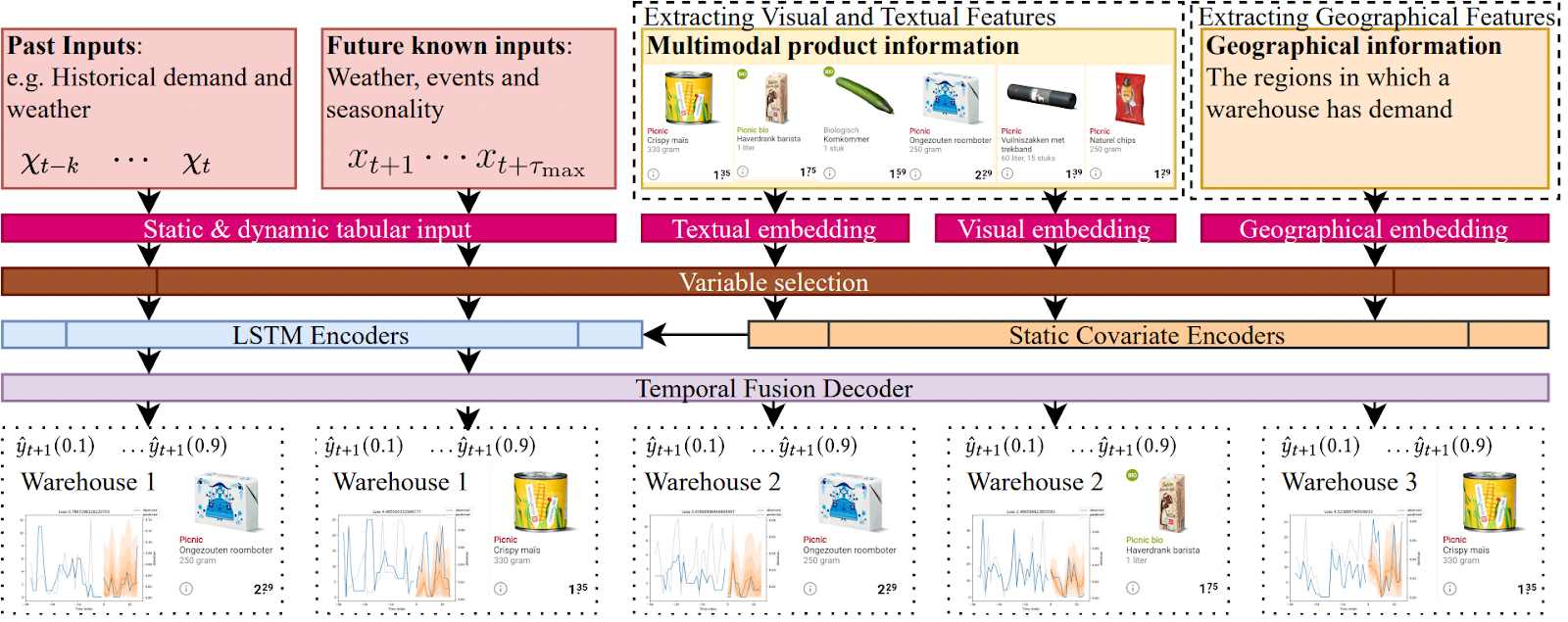
We conducted experiments with two variations of a Multimodal Temporal Fusion Transformer (MTFT), seeking to identify the configuration that offers the best performance. The MTFT is a Transformer-based model that harnesses the power of self-attention to analyze the intricate temporal dynamics across multiple sequences and modalities — an ideal feature for article demand forecasting. This model accommodates a broad spectrum of static and dynamic input: the dynamic features include temporal variables like historical demand and weather, as well as categorical data such as warehouse details, while static input comprises unchanging elements like product images and descriptions. The multimodal features are integrated into the TFT model as embeddings based on the warehouse and product, thereby transforming it into an MTFT. These representations are merged with past and known future inputs, with the output provided at the warehouse, date, time-of-day, and product levels.
The festive experiments
The dataset for the experiment encompasses product descriptions, names, ingredients, and images across a broad product range. The images represent segmented products. In addition, we also have several years’ worth of article demand data for training and evaluating the model. The dataset is characterized by the granularity of warehouse, product, delivery date, and delivery moment (part of the day).
We used data from December 2021 to December 2022 for training (38,206,962 rows) and validation (5,643,705 rows), while the final evaluation was conducted on a test set (10,867,373 rows) from the last two weeks of 2022. Notably, approximately 20% of the dataset is allocated for evaluation. This is only a fraction of the data we have available at Picnic, in our well-structured data warehouse running on Snowflake. Using more data than mentioned above would definitely improve performance, but this small portion of about 50 million rows should be sufficient to see the effect of the multimodal demand forecasting approach using TFT and thus is sufficient for the goal of the experiment.
You might be thinking: Christmas and snow seem to be mentioned often for a blog post in July, we just really like the holidays! The Christmas period, traditionally challenging for demand prediction, is the biggest portion of the evaluation, but so are the surrounding weeks, which represent a more typical demand pattern. The dataset is not uniformly distributed, as some products exhibit less demand. In addition, the dataset contains a degree of product sparsity, reflecting the real-world dynamics where not all products active during the test period were active throughout the training dataset. This is especially true during Christmas when we offer festive products so our customers can have a great Christmas.
Experiment results
We began by evaluating the Temporal Fusion Transformer architecture configuration, focusing on its ability to manage multimodal features. To this end, we experimented with various hyperparameters, hypothesizing that a smaller network may not capture the complexities of these features. As such, we configured and tested both large and small networks. Important to mention is that the network size needs to be large enough to be able to work with product embeddings.
For this blog post, we will use the Mean Absolute Error (MAE), which is a metric commonly used to evaluate the performance of a predictive model. It measures the average magnitude of the errors between predicted and actual values. In simpler terms, MAE tells us, on average, how far off our predictions are from the true values, without considering the direction of the errors. The lower the MAE, the closer our predictions are to the actual values, indicating a more accurate model. There are of course other metrics, but for the sake of simplicity, we report only the MAE here. Evaluation metrics are like sheep: they are happiest in large groups. They also need some trimming now and then, and outliers are good to keep track of.
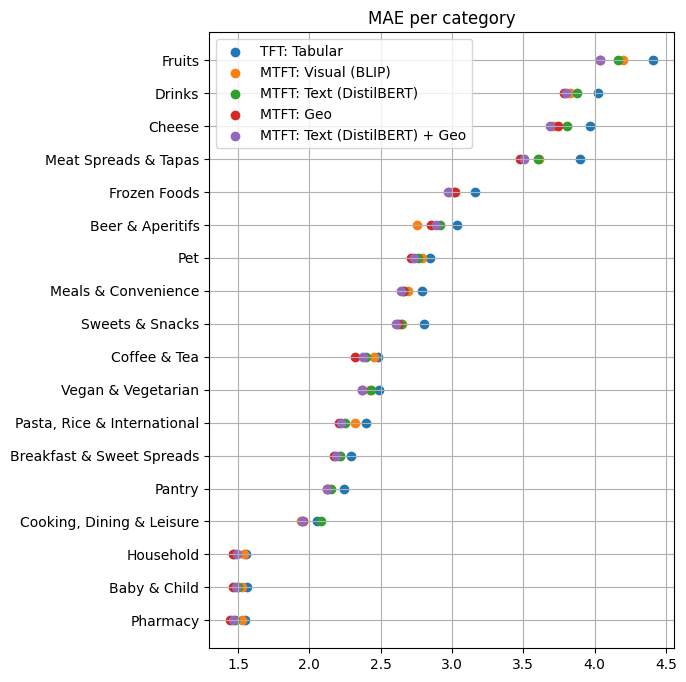
When we analyzed the Mean Absolute Error (MAE) score for various product categories and individual products we found that our MTFT again outperformed the baseline for almost all categories. Categories such as ‘Fruits’, ‘Drinks’, and ‘Meat Spreads & Tapas’ showed the largest improvements in MAE, which may be attributed to the strong, distinct characteristics of these products appealing to our customers. Overall an improvement was visible using the MTFT, showing that it can be useful for better demand predictions!
The experiment demonstrates that multimodal demand forecasting can substantially improve demand prediction. While our findings are promising, it’s clear that there are numerous ways to further enhance these methods. The embeddings can be made more effective and more approaches can be benchmarked. More architectures and backbones can be used for experimentation. But at Picnic we climb the mountain one step at a time. This exploration of Multimodal Temporal Fusion Transformers for article demand forecasting is just beginning, and we look forward to uncovering the full potential of this approach in the future, for example, together with the amazing interns we have at Picnic contributing to this goal!
Conclusion
So here’s the deal: the future of our world doesn’t just lie in the hands of scientists coming up with new forms of renewable energy or politicians arguing over climate policies. No, it’s also right here, in the intricate, fascinating world of demand forecasting research. These experiments with Multimodal Temporal Fusion Transformers (MTFTs) showed us that accurate article demand forecasting can benefit by understanding what type of product is being forecasted. By getting better and smarter at explaining what our products are, we can significantly reduce overproduction and waste, and bring our supply chains in line with the environmental needs of our planet.
Now, we all know the tech world loves a shiny new toy, and right now, large language models like GPT-4 are the equivalent of the latest iPhone release. They’re cool, they’re sexy, and they’re capable of amazing things. But as we’ve found out, they also consume a lot of energy and aren’t necessarily going to save our planet. Due to the positive impact of accurate demand forecasting, the trade-off for energy usage seems to be an easier trade-off. So instead of all focusing on generating texts and images, we might want to look at the deeply impactful world of demand forecasting and its potential for real-world, environmentally-friendly solutions. Demand forecasting models that understand the world will also have an iPhone moment in the next years, which will very likely result in an increase in sustainability in supply chains all over the world
We’re looking for talented data scientists and Python developers who want to do more than just work with the latest and greatest tech (though we do plenty of that too). We need people who want to make a difference, to contribute to something that matters — like Picnic’s fantastic customer experience and contributing to a more sustainable future!
So if you’ve got the skills and the drive to change the world (no pressure!), we want you on our team. We’re not just about experimenting with AI; we’re about using it to make a tangible, positive difference. We run state-of-the-art models at scale. We make customers happy at scale. And increasing the model’s performance and accuracy has a positive impact on the planet at scale. Come join us as we continue to push the boundaries of demand forecasting and create a better future for our customers, and our planet. We can’t wait to see what we can achieve together.
Together, we’re not just forecasting article demand — we’re predicting a brighter, more sustainable future. Are you ready to join us?

