
How we explore and benchmark new technologies for customer feedback classification.
Large language models like GPT have garnered a lot of attention in recent years for their impressive abilities to generate high-quality texts about a broad range of topics. However, when it comes to natural language processing (NLP) tasks such as text classification, are these models also the best option? As data scientists, we figured out the best way to answer this question is by benchmarking new technologies and comparing them with traditional approaches.
At Picnic, we understand the importance of efficient and accurate customer service, which is why we’ve turned to natural language processing techniques to automate the classification of customer feedback as you can read in this and this blog post. But when it comes to making our customers happy, we will always look for new and better ways to do so!
In this article, we’ll share insights from the Advanced Analytics and Algorithms (AAA) team’s two-day hackathon, where one of the hackathon teams explored and benchmarked three different types of models for large-scale routing of customer feedback with text classification. We have compared traditional approaches, a multilingual transformer model, and a service for fine-tuning the GPT-3 model offered by OpenAI.
We’ll first discuss the fundamentals and properties of these various approaches. Then, we’ll share the actual benchmark results from the hackathon. By the end of this post, you’ll have a better understanding of when and how to use different types of NLP models for customer feedback classification.
Traditional approaches
Traditional approaches for text representation such as Bag of Words (BoW) or TF-IDF (Term Frequency-Inverse Document Frequency) combined with contextual information and simple classification algorithms still can give state-of-the-art approaches a run for their money. The simplicity, relatively explainable, and stability these approaches offer are hard to beat.
The simplicity, relatively explainable, and stability these approaches offer are hard to beat.

Firstly, simpler approaches have better performance during inference, meaning it does not take long to classify a single text. Due to only using proven methods and simple calculations, putting the approach in production at scale is cost-effective. There is no need for spinning up costly GPUs to do calculations. And maintenance will take less work since these approaches have been around since 1970 and do not change often.
However, there are some limitations to using traditional approaches. One major drawback is that there is little room for improvement beyond the basic implementation. While more advanced techniques like deep learning models can improve performance through fine-tuning and optimization, this is more limited with traditional methods, and model accuracy will likely plateau earlier.
Another limitation of these approaches is that it does not perform well for multilingual classification. This means that you may need to deploy separate models for each language if it operates in multiple countries and languages, requiring language-dependent data preparation and fine-tuning. This can be costly and time-consuming, especially if the business is dealing with a large number of languages. In addition to that, there is also the cold start problem that occurs whenever the model needs to be deployed for a new language caused by there not being any data available to train on.
Thanks to their simplicity and ease of use, these classics remain classics. It is especially useful if you need to classify large amounts of text in a fast and cost-effective manner.
State of the art: DistilBERT
For the comparison we decided to pick a transformer model that is efficient and quick to train in order to have benchmark results within the two days of the hackathon. Transformer-based approaches for NLP tasks have been achieving state-of-the-art results since they have been introduced in 2018.
DistilBERT is a popular NLP model based on the BERT (Bidirectional Encoder Representations from Transformers) architecture. It is a smaller, distilled version of BERT that is designed to be faster and more resource-efficient while still achieving good performance on various NLP tasks. It has lower memory/CPU requirements and a faster iteration speed than the full BERT architecture making it suitable for a benchmark during a hackathon. There are several advantages and disadvantages to using DistilBERT for text classification.

One major advantage of DistilBERT is that it has good performance. It can achieve state-of-the-art results on many NLP tasks, such as sentiment analysis and text classification. Additionally, DistilBERT has room for further improvement through fine-tuning and optimization. This means that there are many ways of improving the model’s accuracy by training on more data, tuning parameters, and increasing network size. DistilBERT can benefit from training on millions of examples, and there is still potential to improve.
Another advantage of DistilBERT is that it is multilingual. It can be trained on data from multiple languages and can classify text in various languages. This is a significant advantage for businesses that operate in multiple countries and languages. This works well due to the multilingual pre-trained weights being available for this type of model. These pre-trained weights are trained on very large corpora of multilingual data. This makes it possible to deploy a single model that is capable of classifying in a wide range of languages. A very useful property to have for customer feedback routing at Picnic, since we are operating in several European countries.
However, there are also some drawbacks to using DistilBERT. One disadvantage is that at some point it will require GPUs to achieve its full potential. While it is designed to be smaller and more resource-efficient than BERT, DistilBERT still requires significant computational power to train and run effectively at scale.
Another potential downside of DistilBERT is that it requires some training data for new markets. If we want to use DistilBERT to classify customer feedback in a new market or industry, we will need to collect and label data specific to that market. Finally, using DistilBERT is likely more expensive to run in production than other techniques, such as the traditional approach described above. The model is more complex and requires more computational power, which can increase the cost of running the system. Overall, DistilBERT is a powerful and flexible NLP model that can achieve good results on a variety of text classification tasks. However, the potential costs and benefits should be carefully considered before deciding to use it.
Large Language Model: Fine-tuned GPT-3
Fine-tuning the GPT (Generative Pre-trained Transformer) language model using APIs from OpenAI is a new and recently often-discussed approach to a variety of NLP tasks. The Large Language Models (LLMs) currently are mostly available through APIs, although some open-source versions are appearing, for this benchmark we decided to go for the most famous LLM available.

It involves feeding examples of input and output to the APIs of OpenAI. A tutorial can be found here. A big difference between this approach and the others is a dependency on the API of OpenAI, and when using those we encountered several problems regarding reliability. Using external APIs powered by LLMs for text classification has several advantages and disadvantages. The model used is GPT-3, at the time of writing this is the most advanced model available for fine-tuning. And thus it has to be taken into account that newer (and perhaps even comparable open-source) models will likely be available soon.
The approach involves sending a few thousand examples of prompts and answers, to fine-tune the LLM for the task of customer feedback classification. The API can be used to do classification directly but also to create embeddings to later use for doing classifications using simple logistic regression. The results of both approaches were similar.
The big advantage of using GPT is that it requires little training data compared to other machine learning models. The model is already pre-trained on a large corpus of text, which means that it has a good understanding of language and can be adapted to specific tasks with extremely little additional training data. The model is pre-trained on terabytes of data and is likely to perform relatively well on a variety of NLP tasks with no training data at all. This means it allows for solving the cold start problem often encountered in machine learning, a very impressive achievement.
The model is pre-trained on terabytes of data and is likely to perform relatively well on a variety of NLP tasks with no training data at all.
Another advantage of using a (slightly tweaked) GPT is that it is multilingual by default. The model can be further improved on data from multiple languages and can classify text in various languages by default. This makes it a useful tool for businesses that operate in multiple countries and languages.
However, there are also several disadvantages to using a fine-tuned GPT. One potential drawback is that the endpoint can be unreliable. The model is highly complex and can sometimes generate nonsensical or irrelevant responses, which can be problematic if you rely on accurate and predictable text classification. This cannot happen when using supervised machine learning since the output is always within the same predefined range. These outliers can of course be filtered out easily and can be reduced by lowering the temperature of the model, but it can be problematic if drifts occur.
Another disadvantage of using a fine-tuned GPT is that there is a risk of vendor lock-in. This type of service is typically hosted by a third-party vendor, creating a dependency on their availability. Additionally, using endpoints from OpenAI may raise concerns about GDPR (it is not always clear whether using the services is allowed). This is one of the reasons why ChatGPT was banned temporarily in Italy. At Picnic we took care not to use personal data for this experiment to ensure the data is always secure.
Another disadvantage encountered was that the endpoint was sometimes slow when finetuning for the task, requesting predictions, or creating embeddings of texts. This could be a blocker for using the system in a high-speed production environment.
Finally, there is another major disadvantage to running this approach at scale: there is a cost involved in using the endpoint. You typically need to pay for access to the API and for any additional training or support from the vendor. Currently, the costs are low, however, this can be changed in the future.
Evaluation
In order to benchmark the models, we created a test set to evaluate the models. The test set consists of 5 different classes which are slightly imbalanced as they would be in a production environment. The evaluation metric used is the weighted FBeta score since optimizing this results in our customers being helped as best as possible.
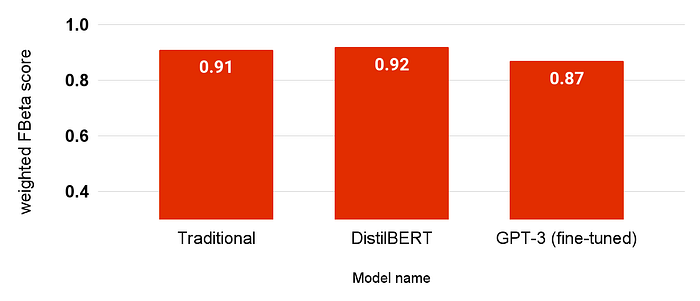
Our evaluation of three different approaches for large-scale routing of customer feedback revealed that traditional TF-IDF and DistilBERT models outperformed the fine-tuned GPT model. The traditional model achieved a weighted FBeta score of 0.91, close to the DistilBERT model’s score of 0.92. These results indicate that the traditional approach is a highly effective and efficient approach for text classification tasks, while the DistilBERT model offers further potential for improvements in accuracy. Important to note that the traditional approach is trained on a much larger dataset of more than 100.000 texts, and the DistilBERT only trained on a fraction of that due to the limitation of benchmarking within a hackathon of two days. This is why we conclude that further improvements are likely possible.
The fine-tuned GPT model also achieved a respectable weighted FBeta score of 0.87, which is promising considering its minimal training data requirements and multilingual capabilities. However, the model’s overall performance did not surpass that of the traditional and DistilBERT models, and it also presented additional concerns such as potential GDPR issues, unreliability, potential vendor lock-in, and cost. Due to the lower speed of the GPT-3 endpoints and the limited time spent on this benchmark, the comparison with this approach is only made on a test set of 4.000 texts.
Therefore, based on our evaluation, we recommend that the traditional approach and the DistilBERT model be considered suitable options for large-scale routing of customer feedback. However, we acknowledge that each project’s specific context and requirements may impact the model choice and encourage continuous experimentation and benchmarking to ensure optimal results. The GPT-3 endpoints’ capability of handling text classification tasks with almost no training data is extremely impressive, but the concerns about the reliability of these endpoints are also worrying.
A nail should be hit with a hammer, but for fixing a flat tire it is a terrible tool.
Concluding: Even though LLMs are extremely impressive, as a data scientist it is good not to use the same tool for every problem. A nail should be hit with a hammer, but for fixing a flat tire it is a hammer is a terrible tool. So be sure to use LLMs for what they are good at as we also do at Picnic, but still consider other technologies for the best possible customer experience!

