

Demand forecasting is critical for any retail company, but even more so for Picnic, an online supermarket selling perishable products with a just-in-time supply chain. This forecast is in the heartbeat of our operations. From ordering products from our suppliers to planning deliveries, every aspect of our app-only supermarket relies on the accuracy of our predictions. If we overestimate demand, we risk throwing away food. On the flip side, underestimating demand leads to disappointed customers who then need to drive to the nearest physical supermarket. Both scenarios we are determined to avoid.
Unfortunately, there is a catch: forecasting demand isn’t as straightforward as other regression problems. Our historical data isn’t just a timeline of past purchases; it’s a tangled web of actual demand and the constraints we faced in the past. Take Mondays, for example. If we did not have enough capacity to deliver to all customers, they might postpone their orders to Tuesday, skewing our perception of actual demand.
Yet, despite these difficulties, we’re up for the challenge of building the best forecasting models to ensure that our customers get exactly what they need when they need it. In this blog post, we will dive into the details of the model that is helping us achieve this goal: the Temporal Fusion Transformer (TFT).
Our Journey Towards the TFT
Before we dive into the technical details, let’s lay out the data and forecast requirements that guided our journey towards utilising TFTs.
When predicting demand for the next day, historical demand is one of the most common data sources we rely on. This data is a strong indicator of future demand, especially considering it’s a time series with visible trends over time. However, our forecasting ambitions extend beyond forecasting just one day ahead. We often need to predict demand for two, three, or even seven days into the future. This type of forecasting, where one predicts multiple time steps ahead, is known as multi-horizon forecasting.
Multi-horizon forecasting requires considering a broad set of variables of different nature. Apart from demand information, we wish to use relevant temporal information(variables that exhibit dynamic changes over time). It could be information unknown in the future, such as the weather, or known in both past and future, such as the day of the week or holidays (consider Christmas and Easter shopping). Lastly, we are also interested in non-temporal static variables, such as the city or number of households in the area, which offer valuable contextual information.
We initially employed gradient-boosting trees to forecast demand. These types of models show robust performance across various forecasting scenarios and allow using different types of features. However, they exhibited a significant drawback discovered during COVID-19: everyone suddenly started buying toilet paper! The model couldn’t extrapolate to values it hadn’t seen during training. As customer behaviour was radically changing, we couldn’t accurately predict demand. Because of this, we decided to look for a novel solution to address these challenges. Our exploration began with Long Short-Term Memory Networks (LSTMs), but we observed no significant improvement in performance. Thus, we delved into more sophisticated models, including DeepAR. However, DeepAR’s architecture does not consider the wide variety of inputs commonly present in multi-horizon forecasting(static and time-varying variables). Therefore, we started looking into TFT.
TFT Overview
The Temporal Fusion Transformer model is a transformer-based neural network specifically designed for time-series forecasting. Google researchers introduced the network architecture in the paper Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting.

The main characteristics of this model are the following:
- Different feature types: It supports temporal and static features. It allows temporal data known only up to the present, such as demand, temporal data known into the future, such as weather forecast, number of confirmed customer orders, and static variables, such as city region and delivery period — morning or afternoon.
- Feature selection: A variable selection mechanism allows it to determine what variables are relevant at a specific moment in time. This enhances the mode’s ability to generalise by concentrating its learning capacity on the most significant features rather than overfitting to irrelevant ones.
- Temporal relationships: It has two different mechanisms to process temporal information. One focuses on short-term interactions, such as daily demand, special events, or unexpected supply chain disruptions, while the other identifies long-term dependencies, such as seasonal trends and payday patterns.
- Model Explainability: Common methods used to explain the behaviour of Deep Neural Networks have limitations with time series because they do not consider that the order of inputs matters. However, the TFT architecture allows us to interpret the reasons behind its predictions on a global scale.
- Prediction intervals: It can predict a range of target values instead of a point for each timestamp. It shows the output distribution and reflects the uncertainty at each timestamp.
So, after seeing the most relevant aspects of this model, buckle up; let’s get technical and dive deep into its components.
TFT Deep Dive
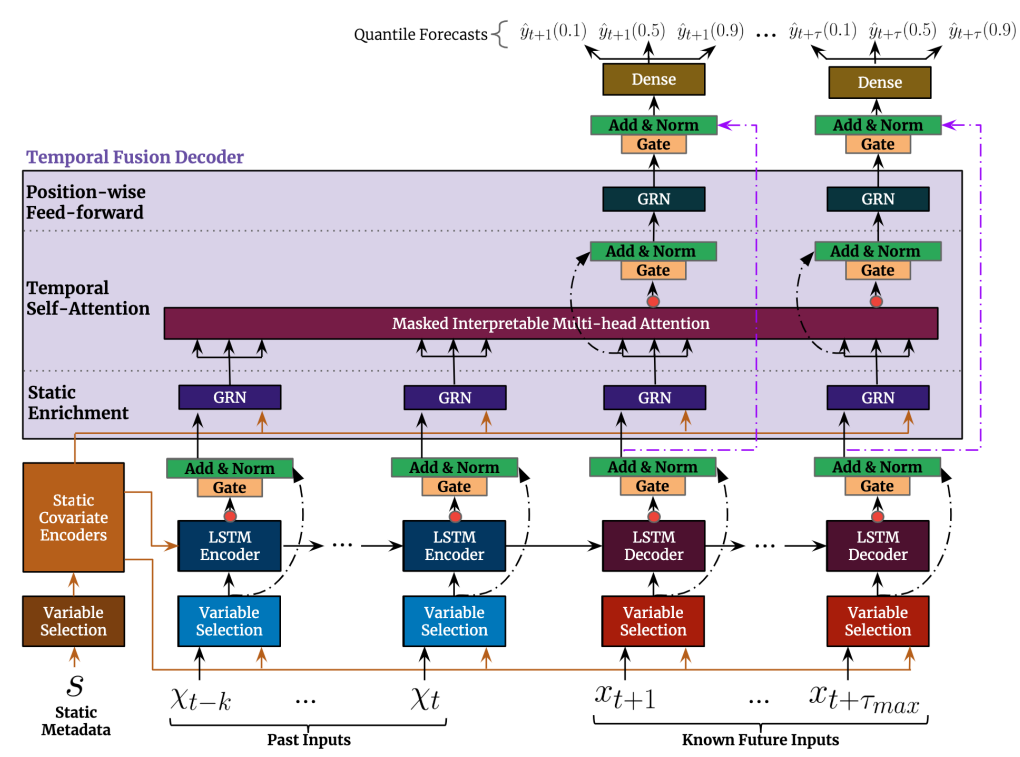
Figure 2 shows the architecture of the TFT. This network shares weights across the different components. Components that share weights have the same colour in the diagram. By sharing parameters across layers, one can reduce complexity and training time while still capturing complex patterns.
Gated Residual Network (GRN)
The gating mechanism is used throughout different components in the TFT. This adds adaptability to the model, allowing it to differentiate between inputs that require complex non-linear transformations and inputs that do not. With the activation function (Exponential Linear Units) the network efficiently selects inputs requiring either simple or complex transformations. Moreover, it has residual connections, meaning that the model can learn to skip inputs if needed, providing more flexibility.
Static Covariate Encoders
Unlike other time series forecasting architectures, the TFT is designed to integrate information from static metadata. It uses GRNs as static covariate encoders to generate four different context vectors, adding information across the following areas of the network:
- Temporal variable selection
- Local processing of temporal representations in the Sequence-to-Sequence layer
- Static enrichment of temporal representations
Variable Selection Networks
In time series, we might have multiple features at hand, and their exact importance and contribution to the target are often unclear beforehand. TFT tackles this challenge by adding variable selection networks. These components not only provide information about which features are the most crucial for the prediction — explainability — but also help filter out any unnecessary noisy inputs that could potentially hinder performance.
There are three different selection networks implemented for each type of input: static covariates, past inputs (known and unknown) and known future inputs.
Local Encoder Decoder
When predicting demand, we work with time series; thus, the sequential order of our data matters. Previous information may provide context that helps us predict future steps. The context in forecasting is very sophisticated, as it involves understanding a wide range of factors, including short-term and long-term patterns. This layer focuses on understanding short-term/ local information.
The LSTM Encoder-Decoder component follows a Sequence-to-Sequence architecture. Such models generate an output sequence by predicting one token at a time. These models excel at encoding features to enhance short-term context awareness and reduce ambiguity. LSTMs have memory mechanisms to regulate the flow of information when processing sequences to facilitate “long-term memory”, yet they encounter challenges when processing lengthy sequences, leading to issues like the vanishing gradient problem. Therefore, it’s better to rely on attention mechanisms for long-term dependencies, as explained in the next section.
Temporal Fusion Decoder
To learn temporal relationships, the temporal fusion decoder uses the output of three layers: the local encoder-decoder layer (short-term context), the Static Enrichment Layer (enrichment of temporal features with static information), and the Temporal Self-Attention Layer.
The self-attention layer employs an attention mechanism inspired by the visual attention observed in animals. This mechanism allows the model to focus on specific parts of the input sequence at each time step, similar to how animals focus on particular aspects of their visual inputs to generate appropriate responses (more on this here). The self-attention layer enables the model to identify long-range temporal dependencies by learning where to allocate attention across the input sequence. Shared weights across all attention heads facilitate the tracing back of the most relevant values, ensuring interpretability. We can explain what the model is paying attention to when predicting. For instance, it might reveal that when forecasting demand, the same day of the week from the previous week holds greater significance than the day immediately preceding it. This understanding allows us to interpret and contextualise the model’s predictions, enhancing our confidence in its forecasts.
Quantile Regression
Instead of predicting a single estimate, the TFT employs quantile regression to generate prediction intervals. This involves simultaneously predicting various distribution percentiles (such as the 10th, 50th, and 90th percentiles) at each time step. Quantile regression is very useful in operational critical tasks since it provides a means to quantify the uncertainty associated with each predicted value, allowing for better decision-making in uncertain situations.
How did we adopt the TFT?
In our journey to predict demand accurately, we implemented two different TFT models. One predicts demand at an article level, for example, forecasting how many bananas our customers will need in the coming weeks. The other model operates at a delivery level, estimating the number of orders we’ll receive in the upcoming weeks.
We started out using Pytorch Forecasting as it had a TFT implementation available. However, now we are considering changing to Darts as it is better maintained and it allows us to continue experimenting with other recent forecasting models.
During the adoption process, we faced several challenges. As the model was relatively new, there were limited online resources available to address our questions and guide us in effectively applying the model to our use case.
Moreover, when training the model, we faced challenges with memory usage. While the TFT allows you to provide extensive context from past timesteps in the training examples, it also results in significant increases in the size of your training data. To address this, we implemented sampling techniques.
Additionally, transitioning to a deep neural network requires more computational power. Unlike gradient boosting trees, which could be trained on CPUs, the TFT requires GPUs. Even with GPUs, training the TFT model takes several hours.
Despite the challenges we faced, we found the effort to be worthwhile. We saw a 20% increase in our forecast precision, particularly benefiting from improved performance in slow-moving articles, which are the most difficult to forecast. Furthermore, the model’s explainability helped us communicate the model’s behaviour to our stakeholders and guided our model development efforts. Thanks to it we could focus on improving the model in areas where we could deliver more value. Lastly, the prediction intervals allowed us to select different quantiles, effectively balancing waste and unavailability in our operations.
Our learnings
We did not want to finish this blog post without first sharing our key takeaways from our journey with the Temporal Fusion Transformer (TFT):
- Embrace the Learning Curve: Implementing a complex model like TFT requires investing time to grasp its intricacies and tailor it to your needs, especially when it is driving critical operational tasks within your company; invest the necessary time to apply it to your use case properly.
- Consider Hardware Costs: Deep learning models like TFT demand significant hardware resources (GPUs), which can increase production costs. Make sure the benefits justify the investment for your particular use case.
- Start Simple: Begin with a strong baseline, potentially utilising simpler models like gradient boosting. In most cases, it may fulfil the majority of your requirements. Only pursue more advanced models if your use case really requires them. If you choose to do so, TFT can be a great option. It excels at understanding complex patterns while providing explainability.
- Stay Curious: The landscape of machine learning evolves rapidly, with newer models like TiDe emerging. Continue exploring to find new ways of improving your forecasts.
If you are interested in reading more about our demand forecasting models, check out our previous blog posts:
- Using Transformers to Cut Waste and Put Smiles on Our Customers’ Faces!
- Running demand forecasting machine learning models at scale
Join us
If you share our passion and curiosity about how we plan to tackle this evolving challenge, we invite you to be a part of our team as a Machine Learning Engineer. Join us on this venture, contributing to the advancement of ML at Picnic by taking it to unprecedented heights!

