
Many companies are working on their digital transformation, transitioning their traditional on-premises deployment to a cloud setup. Other companies, such as Picnic, have started in the cloud and are running a modern cloud native tech stack from the outset. Picnic’s infrastructure design focuses on a rapidly scalable cloud solution. Our vision supports quick growth, staying up-to-date with the latest technologies and focuses our effort on developing our stack, limiting the effort required to keep it up and running.
A few years ago, however, we deviated from this when we set-up on-premises servers, adopting a hybrid approach. This brought with it a whole load of challenges and required a different set of skills to operate. Recently, we reversed this decision and can proudly claim to be a cloud-only company again.
In this blog post we will take you along on our journey from cloud native to hybrid and back again. We will share why we set up on-premises servers in the first place, why we planned our migration back and how we executed this in a safe and stable fashion.
Running on-premises infrastructure
Learning 1: It is hard to learn the skills to run on-premises as a cloud native company
Let’s start with our initial decision to run workloads on on-premises servers. Almost two years ago, we launched an automated grocery warehouse. This warehouse uses robotics and kilometres of conveyor belts to gather and ship the groceries of our customers. For further details about this warehouse, look at this blog post we shared earlier: https://picnic.app/careers/how-we-got-robots-to-do-your-groceries
We installed on-premises servers in this warehouse to operate its systems due to the limit of the speed of light! We wouldn’t be able to consistently achieve sufficiently low response times with cloud-based servers, at least, that is what we initially assumed.
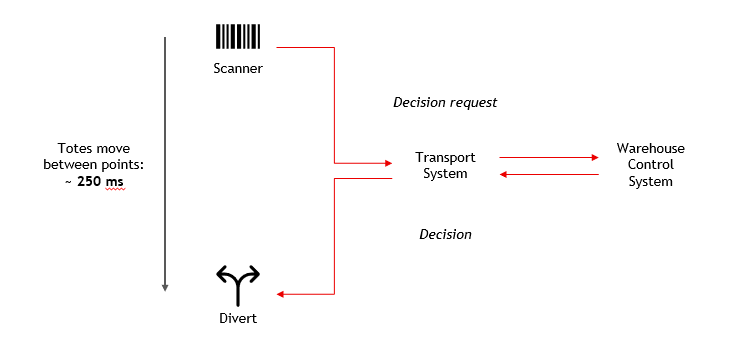
In our automated warehouse, response time is important for various reasons. The most important one is for timely decisions on the conveyor belts. Our goods are transported in boxes with standardised sizes, called totes. These totes move over conveyor belts, past many scanners and diverters. Each time a decision must be made: should the tote be diverted to a different conveyor belt or stay on its current path? Due to the physical distance between scanner and diverter, the decision-making process needs to occur within 250 milliseconds.
Within this 250 ms, a couple of things need to happen in order:
- Send information on the tote to the Transport System.
- Raise a divert decision request to the Warehouse Control System by the Transport System.
- Communicate the decision by the Warehouse Control Systems to the Transport System.
- Execute the divert decision.
If a decision is not made and executed within this 250 ms, the tote will continue straight ahead. If it was supposed to be diverted but wasn’t, it is called a missed divert. Missed diverts cause inefficiency and an excessive amount leads to the warehouse coming to a standstill.
Upon launch of the automated warehouse, adding roughly 50 ms of network latency to each request due to using cloud-based servers was deemed to risky. Accordingly, we decided to install on-premises servers with negligible network latency.
Since then we realised that it is hard to learn the skills to run on-premises as a cloud native company. All of our infrastructure and development processes were focused on cloud computing. We needed to restructure various processes around on-premises servers. Additionally, the skill set required is different. Rather than building on-top of infrastructure provided by a cloud provider, we needed to build redundancies and run maintenance ourselves.
This caused multiple issues:
- High-impact incidents due to less redundancies and expertise
- Maintenance effort increased substantially
- New features had to be implemented twice; for cloud and on-premises servers
On top of this, we aim to launch two more similar sites in the next year, which will only amplify these challenges. Thus, we investigated the option to lift-and-shift our systems to the cloud. The key challenge to overcome was to ensure decisions are taken within 250 ms.
Planning out the migration
Learning 2: The best testing is done in production, but it requires a solid plan
Learning 3: A low-risk migration requires a trade-off between simplifying the migration into multiple parts and minimising the number of maintenance windows.
How do you approach planning such a migration? First, you run an analysis to make sure the desired end-state is achievable. Secondly, you create a plan set-up for success. This requires a clear perspective on the components to migrate and their interdependencies.
Let’s begin with the analysis phase. As mentioned earlier, the 250 ms response time between a scanner and diverter is the crucial use-case to consider. Initially, we weren’t certain about the processing time of the involved systems and we experienced unstable networking from the site to our cloud provider.
Since the launch, we have solved both challenges:
- We strengthened our private network from the site to our cloud provider. We now have a consistent connection with 50 ms of network latency.
- The baseline response time was well below 250 ms.
Solving both challenges gave us confidence the migration can be successful, but we needed to test it. We decided that the best way to test the impact of network latency was to synthetically add latency to our production environment. Our rationale is that we would experience the actual post-migration situation. The best testing is done in production, but it requires a solid plan.
We began testing the addition of synthetic latency to the system in our virtual development environment. Afterwards, we incrementally applied the synthetic latency to the site. We started with 30 ms, and a couple of weeks later increased it to 50 ms (the expected network latency). Throughout the process, we closely monitored the systems and kept close contact with our colleagues on the floor.
One of the metrics we monitored was the number of missed diverts. As mentioned earlier, missed diverts are the consequence of long response times and cause inefficiencies. If the number of missed diverts would increase, we could not run our systems in the cloud. As you can see from the graph, the number of missed diverts stayed stable. Our test was successful and we can continue with the migration!
While specifying the migration scope we had to take some specifics into account. Our automated fulfilment centre operates 20+ hours a day, 7 days a week. Any issue at the start of the shift results in a major delay on the day plan and can cause customer order cancellation. We needed to minimise the risk as much as possible and ensure we could execute the migration and rollback within a four hour maintenance window.
We divided the migration in multiple independent parts to reduce complexity. We determined the risk of each part, and front loaded the most risky parts. The result was a migration split into 4 parts, with limited dependencies between them.
At a later stage, we realised that maintenance windows come with an inherent risk themselves and are a substantial drain on your team. This holds for both the migration team, as for the team on the floor. A low-risk migration requires a trade-off between simplifying the migration into multiple parts and minimising the number of maintenance windows. Eventually, we chose to run two maintenance windows, with two pairs of components.
Executing the lift-and-shift
Learning 4: Despite running extensive validations, rollback tests and production dry-runs, prepare for failure in all parts of the process
Learning 5: Sometimes the less risky solution is taking one step forward, rather than three steps back.
We prepared for the lift-and-shift by implementing the technical requirements, determining the steps, and executing validations and tests. The deliverables of this process were threefold:
- Technical runbook: detailing which steps and scripts to execute for the migration and rollback
- Operational runbook: detailing the overall plan, timeline and rollback criteria
- Prepared migration team: able to execute both runbooks
The technical runbook was executed multiple times in our development environment and dry-run in production. The purpose was to improve the runbook itself, but also to train the team.
Despite running extensive validations, rollback tests and production dry-runs, we prepared for failure in all parts of the process. This is where the operational runbook played a key role. We needed to ensure we could call in experts to solve all sorts of issues during and after the migration. The operational runbook documented these experts. It also clarified the maximum allowed time for each stage, and who decided between success and failure at each stage.
With these runbooks in hand, we were ready to start the migrations in dedicated nightly maintenance windows. As expected, we faced multiple unexpected challenges. But due to the combination of runbooks and a prepared team, we were able to tackle them. During these challenges we discovered that sometimes the less risky solution is taking one step forward, rather than three steps back.
One example of this is related to barcode scanning and URL redirections. At the automated warehouse we use multiple types of devices to scan barcodes. One type of device didn’t scan barcodes anymore after the migration. As scanners being able to scan is a crucial part of the operations, we needed to fix it. We quickly figured out the issue. It was caused by the URL redirection that we set-up to simplify the migration.
Then there were two solutions: rollback the migration or update to the new URL. While updating the URL is not trivial, we already planned the approach for this change. We deemed it less risky to execute this change rather than the entire rollback. This change required access the migration team didn’t have, but this is where the operational runbook came into play. We had an expert standing by.
Closing
After two successful nightly maintenance windows, we migrated all our applications from on-premises to the cloud. Since the migration, the additional latency hasn’t caused any issues, there have not been any major infrastructure incidents, and numerous features are unlocked. While lift-and-shifts are common projects, the dependencies and required continuity of the systems made it complex. By splitting it into simpler parts and preparing a solid migration and rollback plan we were able to successfully migrate. While we don’t plan to execute a similar migration again, we have plenty more complex projects planned down the road where our learnings will be crucial.
What are your learnings from this story? Our learnings in the project are five-fold, but the common theme is about making trade-offs around risks and preparing in depth. Through our diligent process we manage to migrate on-premises workloads in an live automated warehouse to the cloud while limiting the impact on operations.



 Eric Smith
Eric Smith








