
(Written by @masoud.alali.94 & @joao.nogueira01)
In the previous blog posts, we’ve explored how Picnic’s Page Platform has revolutionized the way we build our mobile grocery shopping experience. As a mobile-only online grocery retailer, our success depends on delivering an exceptional app experience to our customers. When evolving our platform, we focused on two key goals:
- Minimizing time to market by shipping changes instantly without requiring app updates.
- Enabling non-engineers — such as designers and product owners — to modify the app experience without needing deep technical expertise.
The Page Platform was our solution: a powerful server-driven UI framework that allows us to create and modify app screens instantly without requiring app updates. It defines both the visual layout and the underlying data requirements in a unified way, enabling rapid development and seamless updates. This framework has transformed how our teams work together, breaking down barriers between engineers, business stakeholders, and analysts. However, as with all technology solutions, we continuously look for ways to improve. In this post, we’ll share our journey of migrating the templating language for our dynamic pages from Handlebars to JavaScript. Before focusing on what to change, however, it was important to reflect on how the existing approach fit our use case, what we definitely like and intend to keep, and what we’d like to improve on.
A small reflection on the Platform’s status quo
The Page Platform was built with configurability in mind, which means we wanted to have our page definitions configurable on our backend. This was the architecture that best aligned with our goals and requirements, since it unlocked:
- Configurable pages on our backend system.
- Shipping new features and changes without needing app release in almost real-time.
- Creating tools around such platform to allow analysts and non-developers to configure pages without needing deep technical expertise.
To describe such configuration, initially we chose Handlebars as our templating language. We knew Handlebars was a flexible and simple enough templating language and thought that it would allow us to build and grow our Page Platform. However, we learned that it also has its drawbacks. Let’s break it down:
What we liked about Handlebars
- Handlebars is easy to extend and easy to learn.
- It is easy to integrate and set up.
What drawbacks we saw with Handlebars
- Its syntax is very rigid.
- The introduction of simple logic required such logic to be implemented in Java (and exposed in Handlebars as helpers), which meant a full BE release cycle for small logic introductions.
- As a templating language, it wasn’t suitable for complex logic requirements.
- It lacked IDE support, resulting in a frustrating and error-prone development experience.
- The lack of supported logic also meant that output validation was limited, resulting in frequently breaking the output JSON contract.
As such, we concluded that, even though this Server-Driven UI approach was a clear step up for us, the choice of Handlebars as our templating language was not the best.
We needed a solution that seamlessly integrated with our backend, supporting Calcite queries (our query infrastructure that allows running SQL queries across all kinds of data sources) and other Java logic while also enabling more complex UI logic without relying on Java-based helpers. Additionally, developer experience was a major consideration — we wanted a system that made it easy to write safe, maintainable code, allowed for static analysis, supported local debugging, and leveraged widely available resources for onboarding.
Since our front end already used React Native, extending JavaScript to the server side was a logical step toward simplification. This approach, combined with TypeScript for type safety, emerged as the ideal choice. It would give us flexibility, robust tooling, and familiar development experience with JavaScript throughout our entire UI layer. And to make this work within our Java backend, we needed the right runtime solution.
Exploring Implementation Options
With JavaScript as our chosen language, the next challenge was deciding how to run it on the backend. We explored two main approaches:
Standalone JavaScript services
The most straightforward way to execute JavaScript on the server.
- Pros: Easy to set up, aligned with traditional JavaScript backend architectures.
- Cons: Introduced operational complexity — we would have to learn how to run JavaScript services in production at scale. Additionally, it lacked direct interoperability with Java, requiring more services and contracts, which added friction to the release process. Moreover, communication with our Java BE services would represent extra network communication;
Running JavaScript inside our Java application
A more integrated approach that would allow JavaScript execution within the JVM.
- Pros: Seamless interoperability with Java, no additional services to manage;
- Cons: We lacked experience with this approach and weren’t sure how to implement it effectively;
Given the benefits of seamless interoperability and reduced operational overhead, we opted to run JavaScript within our Java application.
Adopting GraalVM
As a polyglot virtual machine, GraalVM allows us to run multiple languages — including JavaScript — within the same Java runtime environment. By adopting GraalVM, we could execute JavaScript code seamlessly within our backend Java application, allowing for page templates defined in JavaScript to be evaluated in the JVM.
A critical requirement was ensuring safe interoperability between Java and JavaScript. Sharing Java objects directly with JavaScript can unintentionally expose internal methods and properties we don’t want to be accessible, as while we want to expose the fields of a certain Java object, the same doesn’t apply to common methods like `toString`. Instead of allowing unrestricted access to Java classes and methods, we crafted a custom API based on a promise-driven structure (supporting interoperability with asynchronous Java methods). Each page is represented as an async function, and we subscribe to this promise from Java, providing only the specific parameters required for each page render. To enable JavaScript to invoke certain asynchronous Java methods (data retrieval from Calcite being the clearer asynchronous use-case), we extended this promise-based API, allowing JavaScript to call back into Java in a controlled, asynchronous manner. By controlling this Java to JavaScript interaction, our setup is efficient, scalable, and extensible, giving us the benefits of JavaScript’s flexibility within the stability and performance of the Java backend.
Challenges we faced
Our use case required careful orchestration to ensure optimal performance. Each GraalVM context — a necessary component for executing JavaScript — can handle only one script execution at a time. A naive approach, where a new instance is created for every request, would fail to leverage GraalVM’s internal optimizations, significantly impacting execution performance.
Since creating new contexts is computationally expensive and their initial executions are slow due to the lack of runtime optimizations, we implemented an ObjectPool to efficiently manage and reuse them. This pooling mechanism allowed us to minimize the overhead of repeatedly instantiating contexts, instead recycling them to handle incoming executions more efficiently.
Page Rendering Flow: An Overview
Before diving into the specifics of our tooling, it’s important to step back and look at how our Page Platform operates at a high level. The process of rendering a page follows this general flow:
- The app requests a page by its ID and relevant parameters.
- This request is sent to our Java backend service.
- The backend retrieves the corresponding JavaScript code for the requested page and executes it on the server.
- During execution, the JavaScript code interacts with Java components as needed — for example, to fetch data using Calcite (our data retrieval API) or, in the future, to trigger side-effect-driven actions.
- Once all necessary data is retrieved, additional business logic expressed in JavaScript may be executed on the server.
- The final output is a serialized JSON structure that adheres to a predefined contract describing how the page should be rendered. This response is passed back to the client via Java, completing the request/response cycle.
With this foundation in place, let’s explore how we bridge JavaScript and Java to make this process seamless.
Bridging JavaScript and Java
To define our pages in JavaScript, we needed to establish a clear contract between JavaScript and Java. Each page’s execution had to produce a well-defined output that Java could process, ensuring the correct JSON response was generated for the app to accurately render the page.
To achieve this, we designed the following API:
- JavaScript exports a map of page IDs to asynchronous functions. Each function, when executed, resolves to a JavaScript object that adheres to the predefined Page API.
- Java provides an interoperability API, enabling JavaScript to invoke asynchronous Java methods when needed.
This setup ensures seamless communication between JavaScript and Java, allowing for efficient data retrieval, business logic execution, and page rendering.
The JavaScript code executed in our system is version-controlled in a Git repository, ensuring that every change is tracked and represented by a unique Git revision. For each revision, a new JavaScript bundle is generated. This bundle is designed to adhere to a specific API, which we outline below (example of a `home-page` simply with a title section):
const Pages = {
'home-page': async () => {
return {
title: "Home Page"
}
}
}
export default Pages;
Similarly, we had to establish a clear API that would allow developers to request data from Calcite queries directly within the JavaScript framework (as explained in a previous blog post from this series). This interaction had to align with our promise-driven infrastructure. To accomplish this, for each page rendered, we bind a query method to the GraalVM context, which delegates to the Calcite query resolution logic, effectively creating a bridge between the JavaScript and data query layers.
This approach enables seamless data retrieval, following a simple API structure, as shown below:
await query('SELECT * FROM table_name', {'parameter_key': 'parameter_value'})
This well-defined API not only enables seamless interaction between the JavaScript and Java layers in production but also facilitates a streamlined local development environment. Using a local Node.js server, JavaScript developers and page authors can significantly shorten their feedback loop. In this setup, queries and invocations are routed to an internal REST endpoint, providing the necessary data for page rendering — all without requiring new versions to be configured in deployed environments for each iteration (more on this later in a blog in this series).
JavaScript-Powered Templates
Moving to JavaScript for templating was already a significant upgrade from our previous Handlebars implementation, giving us the full power of a programming language to build server-side pages. While JavaScript alone provided great flexibility, we knew from experience that typed languages are crucial for maintaining reliability across our systems. Since our React Native app was already built with TypeScript, extending this type-safe approach to our Page Platform was a natural choice. TypeScript brings additional benefits like auto-completion, build-time validation, and consistent code style enforcement through formatters and linters. With this in mind, we outlined a set of key requirements for our new setup.
Key Requirements of Our New Pages Framework
- TypeScript Compatibility: Full type-checking, autocomplete, and build-time validation.
- Syntax Flexibility: A clean, intuitive syntax that is easy to remember and maintain.
- Testability and Maintainability: Code that’s easy to test and update.
- Backend Integration: Seamless integration with our backend and data sources.
- Support for Complex Logic: Flexibility for reusable and intricate logic in templates.
- Data Query Imports: Ability to import SQL queries directly into pages for easy integration.
With these requirements in mind, we started exploring different options for our setup. Below is a brief overview of the approaches we considered.
Using Plain JS objects
Our first approach was to use type-safe JavaScript objects within various functions, nesting them to ultimately define the entire page structure.
export const HomePage = (): IPage => {
return {
id: 'home-page',
body: {
type: 'BLOCK',
...
},
...
}
}
This method was type-safe and straightforward. However, as the objects grew in size, they became harder to maintain. Additionally, working with plain objects all the time was not the most enjoyable experience for developers.
Using Functions as Components
To improve upon the previous approach, we wrapped each building block in functions, using them instead of plain objects.
export const HomePage = (): IPage => {
return Page({
id: 'home-page',
body: Block({
...
}),
...
})
}
This solution was an improvement, providing more reusable components while maintaining type safety. However, as our components became more complex, their definitions grew larger and harder to manage.
Using JSX
Inspired by React’s JSX setup, we explored the possibility of integrating JSX into our framework. With JSX, we could create reusable components and provide a developer-friendly environment with robust IDE support, including AI-powered suggestions. Additionally, we could develop a custom engine to parallelize component rendering and fully control the framework’s execution flow.
To implement this, we built core components as the foundation and leveraged TypeScript’s JSX setup to develop a custom engine capable of processing and resolving nested components.
export const HomePage = () => {
return <Page id={'home-page'}>
<Block>
...
</Block>
</Page>;
};
This approach proved to be type-safe, intuitive, and enjoyable to work with. The familiar syntax made it easier for our team to adopt, while our custom engine gave us greater control over component resolution, allowing us to optimize performance where needed.
After choosing TypeScript and JSX as our core setup, the next step was to make it compatible with our production environment, GraalVM. To achieve this, we needed to transpile our code into Vanilla JavaScript with a single main entry point. Following best practices, we used bundlers to handle this process efficiently.
Bundling
To optimize our approach, we introduced a bundling process to generate production-ready bundles that seamlessly integrate with our backend. Bundling ensures compatibility with production environments, and we developed custom plugins to enable advanced functionality, such as importing SQL query files that transforms SQL files into JavaScript functions, complete with support for dynamic parameters.
Additionally, we version each bundle output, allowing us to load specific versions of the code as needed. Having a bundler also gives us the flexibility to add new dependencies and include them in the bundle without impacting the backend system. This centralized approach makes dependency management much more efficient.
Testing
For testing, we used an infrastructure that supports parallel execution and integrates seamlessly with our bundling setup. This enables us to create test environments that closely mimic production. In addition to standard testing — such as unit, functional, performance, and snapshot tests — we developed custom tests tailored to our pages, including end-to-end (E2E) and visual regression tests. These ensure consistent behavior across different environments and help us catch issues early.
Development Server
To further streamline development, we set up a local development server and integrated our network proxy to capture and redirect application requests to the local implementation. Additionally, we reused the custom plugins from our bundling and testing setup to ensure that the dev server mimics the bundler’s behavior. This creates a consistent experience across development, testing, and production environments.
Our setup allows us to seamlessly switch between real and mocked data sources, providing flexibility for accurate and immediate testing. When mock data isn’t used, we implemented local versions of data providers to communicate with REST endpoints, effectively simulating our production environment. In production, however, API bridges between JavaScript and Java handle direct connections to our backend.
One key difference between our local and production environments is that GraalVM, which we use in production, provides a JavaScript runtime but lacks full Node.js functionality. This required us to account for certain limitations and ensure our setup remained compatible across both environments.
In conclusion, this comprehensive setup — featuring TypeScript, JSX, bundler, testing environment, and local development server — empowers us to develop, test, and deploy server-side pages with ease. With real-time feedback, production compatibility, and flexibility for complex logic, our approach simplifies the development process and reduces time to production, resulting in a highly maintainable and efficient system.
After all, how do new versions reach Production?
As mentioned earlier, the JavaScript framework is version-controlled in Git, with each change corresponding to a new Git revision. To ensure our running environments stay up to date with the latest changes, we implemented a GitHub webhook that notifies our backend deployments of incoming updates. Upon receiving a notification, the backend fetches the latest changes from the repository, generates the updated JavaScript bundle, and replaces the deployed version with the newly committed code.
This process ensures that the latest revisions are seamlessly integrated into the environment. The overall flow can be summarized as follows:
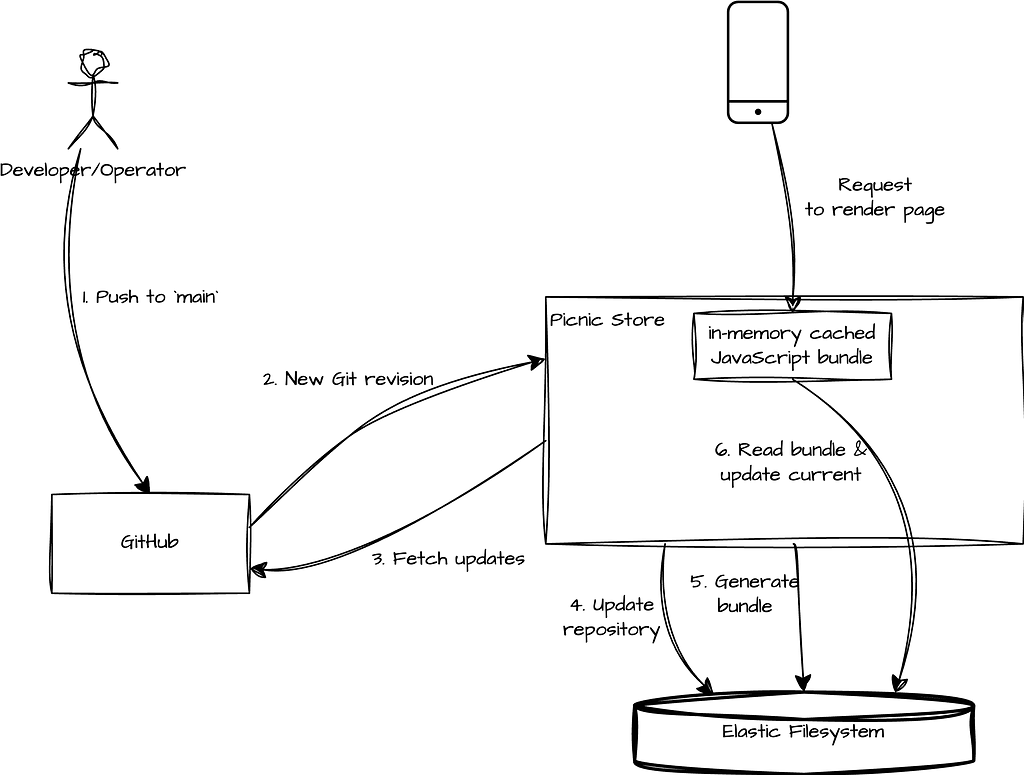
How resilient is our system, though? What happens if GitHub is down? Do we ensure our system can withstand third-party outages? This is where the Elastic File System (EFS), mentioned in the diagram above, comes into play.
But what exactly is an Elastic File System? As Amazon describes it:
“Amazon Elastic File System (Amazon EFS) provides serverless, fully elastic file storage, allowing you to share file data without provisioning or managing storage capacity and performance.” — source
So, how does this help? First, our backend application is deployed across multiple replicas. We don’t want each replica to depend on a live connection to GitHub to fetch its own version of the Git repository. To solve this, we store both the updated repository and the generated bundles in the Elastic File System, which all Picnic Store pods can access.
In the event of a GitHub outage, not only do we have an up-to-date copy of the Git repository (as of the last successful update), but we also have the generated bundles stored in the EFS. This ensures that we avoid the overhead of regenerating bundles every time, and more importantly, it removes the direct dependency on GitHub, improving the overall resilience of our system.
Migrating Old Templates
After introducing our new Page Framework, we faced a significant challenge: managing templates written in two different engines — Handlebars (HBS) and our new JavaScript-based framework. Maintaining both was not only cumbersome but also inefficient. Changes had to be applied to both systems, sharing logic between them was difficult, and testing became a bottleneck.
At the time, we had approximately 1.200 HBS templates, ranging from large, complex templates to small, reusable components. Manually migrating all of them was impractical — it would have required significant time and resources from the team. Additionally, testing each template after migration was tricky, making automation a necessity.
Migrating HandleBars templates to TypeScript
We explored multiple strategies to migrate the templates effectively. Here’s how we tackled the problem:
Exploring AI-Based Solutions
Initially, we experimented with AI tools. Using simple prompts like:
“I have this HBS template with these properties. Migrate it to JS while considering [specific logic or structure].”.
While AI provided interesting starting points, it couldn’t produce results close to what we needed. We realized that while AI could assist in refining or validating templates, it couldn’t handle the migration reliably on its own.
Parsing HBS Templates at the AST Level
Our next idea was to parse HBS files and convert them at the Abstract Syntax Tree (AST) level into JavaScript code. In theory, this approach seemed promising, but we encountered significant challenges:
- Structural Differences: HBS AST and JavaScript AST have fundamentally different structures, making conversion highly complex.
- Template-Specific Syntax: HBS relies on helpers and its own syntax, complicating AST transformation.
- Existing Workarounds: We employed numerous hacks to generate JSON results from HBS templates, which made parsing and comprehending the AST even harder.
Given these complexities, we decided to abandon the AST-level approach in favor of a simpler solution.
Hacking the HBS Compiler
We found an unconventional yet effective solution: modifying the HBS compiler itself. Handlebars are designed to allow custom helpers and logic injection. By leveraging this, we reconfigured the compiler to output JavaScript code instead of rendering templates.
For example:
- {{each …}} was converted to JavaScript’s .map() method.
- Instead of resolving variables during rendering, we replaced them with their actual variable names in the output.
This approach allowed us to generate JavaScript representations of the HBS templates. While this method worked, it still required additional steps to meet our framework’s requirements:
- Syntax Adjustments: Some templates had syntax issues caused by previous hacks or the transformation itself.
- JSX Conversion: Since our new framework used JSX syntax, we needed an additional transformation step.
TypeScript Integration: Our framework already supports TypeScript and we preferred to migrate directly to TypeScript and have full type safety instead of having VanillaJS as a middle step.
Integrating AI for Migration Refinement
Once we had a basic migration pipeline, we revisited the use of AI for improving the migrated templates. We tried both GPT and Gemini to find the more accurate result for our use case, and in the end, we found in our case we got better results using Gemini. AI helped us to:
- Fix Syntax Issues: AI reviewed the migrated JavaScript templates, cross-checking them against the original HBS templates to identify and resolve syntax errors.
- Ensure Semantic Accuracy: It also validated that the migrated templates maintained the original logic and structure.
AI proved even more helpful when defining TypeScript types. By analyzing parameter usage and inferring types, it generated TypeScript interfaces for our page props, resulting in a more robust third version of the templates.
Building a Dashboard for Manual Review
With three versions of each template — original HBS, AI-refined JavaScript, and TypeScript-enhanced JavaScript — we needed a way to finalize the best version efficiently. To streamline this process, we developed a web-based utility dashboard. This tool:
- Listed all templates and their dependencies.
- Allowed side-by-side comparison of the original and migrated templates.
- Enabled developers to select the highest-quality version as the base for further manual improvements.
Using the dependency graph, we prioritized migrating leaf nodes first, working upwards to root pages. This incremental approach ensured consistency and simplified testing.
Testing the Migration
The primary goal of the migration was to ensure that the new JavaScript (JS) templates replicated the exact logic and output of the original Handlebars (HBS) templates. To validate this, we adopted a comprehensive testing strategy that involved generating test data, automating comparisons, and conducting end-to-end evaluations. Here’s how we approached each aspect:
Generating Test Data
To test effectively, we needed realistic sets of input props and expected outputs for each template. Since our templates varied in complexity, we used multiple data sources and strategies to generate the required test data:
- Using JSON Schemas — Some HBS templates had predefined JSON schemas for their accepted props. These schemas defined the structure and constraints of the input data. We utilized AI tools to generate mock props based on these schemas. For example, a schema specifying a name as a string and age as a number allowed us to create diverse sets of mock inputs ({ name: “Alice”, age: 30 }, { name: “Bob”, age: 25 }). These mock props were then used to render both the HBS and JS templates, enabling us to compare their outputs.
- Extracting from Backend Logs — For templates without schemas, we turned to logs from our backend rendering engine. These logs contained real-world examples of props passed to templates during execution, along with their rendered outputs. We processed these logs to extract structured test cases, ensuring that the props and expected results were realistic and reflective of actual use cases.
- Manual Data Compilation — In rare cases where neither schemas nor logs were available, we manually curated test props. Developers reviewed the template logic to infer the required inputs and wrote scripts to generate a diverse range of props. These scripts rendered batches of templates with various prop combinations, saving the outputs for comparison.
Automated Test Generation
With the generated test data in hand, we automated the test generation of the template using some scripts to generate JavaScript tests in the testing environment we have for our pages. The process was as follows:
- Baseline Output Generation — We rendered each template using HBS and saved the output as the baseline using mock input (expected result).
- Migrated Template Testing — The same input was passed to the migrated JS templates and the outputs of the HBS and JS templates were compared.
- Identifying Discrepancies — If the outputs differed, the test was flagged for manual review. These flagged tests were reviewed manually to determine whether they represented actual issues or acceptable differences. For example, an output with minor differences in spacing or naming conventions might be approved, however, logic mismatches might be flagged for fixing.
End-to-End (E2E) Testing
To validate templates in the context of entire pages, we implemented an end-to-end testing setup. This process ensured that the migrated templates integrated seamlessly with the surrounding system:
- Full Page Rendering
The entire page was rendered using the original HBS templates as well as the migrated JS templates.
The rendered pages were compared to identify any visual or structural differences. - Normalizing Differences
Some differences were unavoidable due to updates in the migration process (e.g., switching from named colors to hex codes).
To address this, we developed transformers to unify outputs for certain attributes, such as normalizing color formats, standardizing date/time formats and JSON property name casing. - Internal Testing and Deployment:
Once E2E tests passed, we deployed the migrated templates to our development environment.
The templates were then tested by internal teams for further validation before being released to production.
Final Release Process
To finalize and release a migrated template, we followed a structured pipeline:
- Run Automated Tests
Execute test cases and review discrepancies. - Perform E2E Validation
Render and compare entire pages for consistency. - Deploy to Development
Enable the new template in a development environment for internal testing. - Monitor and Roll Out
Monitor internal feedback and make necessary adjustments before deploying to production.
Final Thoughts on Migration
Migrating over 1.200 templates was no small feat, but through a combination of automated tools, AI assistance, and thoughtful manual review, we successfully transitioned to a unified, TypeScript-based framework.
Automation, helped us to reduce human errors and gave us initial migrated files, which we couldn’t achieve in a reasonable timeframe by manually migrating each HBS template!
This migration not only streamlined our development process but also set the stage for easier maintenance, better performance, and a consistent developer experience moving forward.
The End of a Journey, The Start of a New Era
Moving from Handlebars to our custom TypeScript framework was not just a technical necessity but a transformative journey for the team. This migration reduced complexity, unified the template logic, and empowered us to leverage modern development practices like TypeScript’s strong typing and JSX’s expressive syntax. By combining automated tools, AI-powered improvements, and rigorous manual oversight, we ensured a seamless transition that preserved functionality while enhancing maintainability. Our innovative use of the Handlebars compiler, GraalVM integrations, and structured testing processes allowed us to bridge the old and new systems effectively.
This move not only modernized our codebase but also set a precedent for how we approach large-scale system overhauls — prioritizing automation, collaboration, and meticulous testing. It’s a testament to the team’s creativity and adaptability, showcasing how challenges can inspire inventive solutions. As we continue building with this new framework, we’re confident in its scalability, performance, and ability to support the evolving needs of our developers and users.
This article is part of a series of blogposts on the architecture behind our grocery shopping app. Hungry for more? Chew off another bite with any of our other articles:
- In Faster Features, Happier Customers: Introducing The Platform That Transformed Our Grocery App, we share the motivation behind our architecture and give a general introduction.
- Define, Extract and Transform inside Picnic’s Page Platform gives a high-level overview of our journey towards a platform that enables querying data and transforming it into rendering instructions for the client.
- In Enabling rapid business use case iteration with Apache Calcite, we go into great detail of why we chose Apache Calcite as the tech behind our query engine, and how we are using the technology.
- Picnic’s Page Platform from a Mobile perspective: enabling fast updates through server-driven UI details our approach to implementing server-driven UI in our mobile apps.
- Tackling Configuration: creating Lego-Like Flexibility for non developers details how we empower non-developers within our Page Platform.
Java Meets JavaScript: A Modern Approach to Dynamic Page Rendering was originally published in Picnic Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.



 Eric Smith
Eric Smith








