The declarative paradigm is becoming ubiquitous in data engineering, to the point we sometimes feel we became YAML developers. Yet, I’ll argue it’s a good thing! Let’s take a step back and look at what it means to be declarative, and how it impacts the data systems we build.
Data & logic
Fundamentally, a data platform is made of 2 pieces:
- Data. On the frontend, we find the actual files, tables, dashboards and reports delivered to users. On the backend, we operate with raw data and staging layers. This is the “state” of the systems, i.e. the value of the memory and storage at a given point in time.
- Logic. The “code”, i.e. the set of instructions to mutate the state: usually this is a mix of business logic (SQL for data transformations) and infrastructure logic (orchestration, integration, and the like).
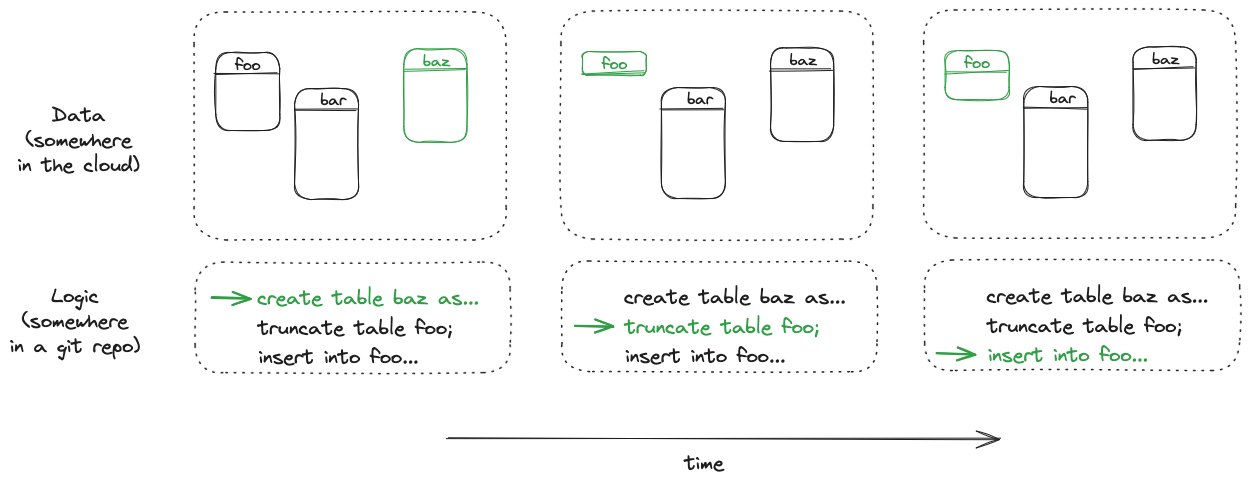
With many data platforms, logic in its traditional sense — computer programs — is slowly being replaced by metadata: we declare our needs next to the data (for example orchestration requirements) and some system is handling it for us (such as figuring out dependencies and spawning containers to effectively orchestrate those needs).
Should all the logic — the metadata — be laid out in YAML? And how did we come to that? Let’s explore some of the simple ideas behind these declarative data platforms, and why they help deliver more data, more reliably.
Declarative languages
Data engineering always had its roots in the declarative paradigm, due to the success of declarative querying languages, SQL being the undisputed champion. The idea behind those languages is to describe the shape of the desired result and let the system figure out the necessary steps to achieve that result:
"2" data-code-block-lang="sql">select min(amount)
from sales
where country = 'NL';
It’s a very different approach than traditional, imperative languages, where listing computation steps is the responsibility of the developer:
"2" data-code-block-lang="python">minimum = float('inf')
for sale in sales:
if sale.country == 'NL':
minimum = min(minimum, sale.amount)
SQL allows us to describe “what” we want, Python allows us to describe “how” we want it.
Behind the scenes, a declarative query is executed as imperative steps by the engine:

While I’m not attempting to compare language features, it is easy to recognize the elegance of SQL: no side effects, no memory management, and all the optimizations and correctness validations are delegated to the query engine. Anyone can write it — that’s the whole point.
Declarative systems, and why they matter
There’s of course more to data engineering than querying and transforming data, and the logic also contains many nasty parts, such as orchestrating different components, moving data across multiple systems, recovering from failures… you name it. Modern tooling in the data ecosystem is providing declarative interfaces to solve those challenges.
It’s the same idea as SQL: users describe the desired result, and the hard work of figuring out the steps to reach that state is left to the engine.
In data engineering, YAML is getting increasingly popular to declare those desired states.
For example, a data model:
"2" data-code-block-lang="yaml">name: sales
config:
schema: mart
materialized: table
columns:
- name: amount
type: decimal
description: Sale amount
or a pipeline:
"2" data-code-block-lang="yaml">name: pipeline_sales
tasks:
- name: extract
action: fetch_from_storage
path: data/raw/sales.json
- name: transform
action: build_model
model_name: sales
What’s really happening, beyond mere configuration, is the declaration of the desired state: Hey <data modeling platform>, there should be a sales model with a decimal column amount, do what’s necessary. Hey <pipeline platform>, there should be a pipeline named pipeline_sales with two tasks, do what’s necessary. If those entities already exist in a different state, the responsibility of figuring out the differences to bring them up-to-date is left to the systems.
This approach brings many benefits. From a technical perspective, bringing a change to production means simply updating some files, and letting systems figure out how to update accordingly and reach the correct state. When things go south, state reconciliation is easier. It also facilitates systems’ integration with each other, as declarative files can easily be parsed and acted upon. Mass migrations are almost trivial because they can be automated.
From an automation perspective, it makes it trivial to implement GitOps: a git repository is the single source of truth for the data platform components, which are automatically updated as soon as changes are merged, ideally in a CI/CD process.
Declarative files also scale much better: they are easy to write, easy to review, and even more importantly don’t require specialized programming knowledge: data analysts are not limited to data consumption anymore but can easily contribute to any component of a declarative data platform.
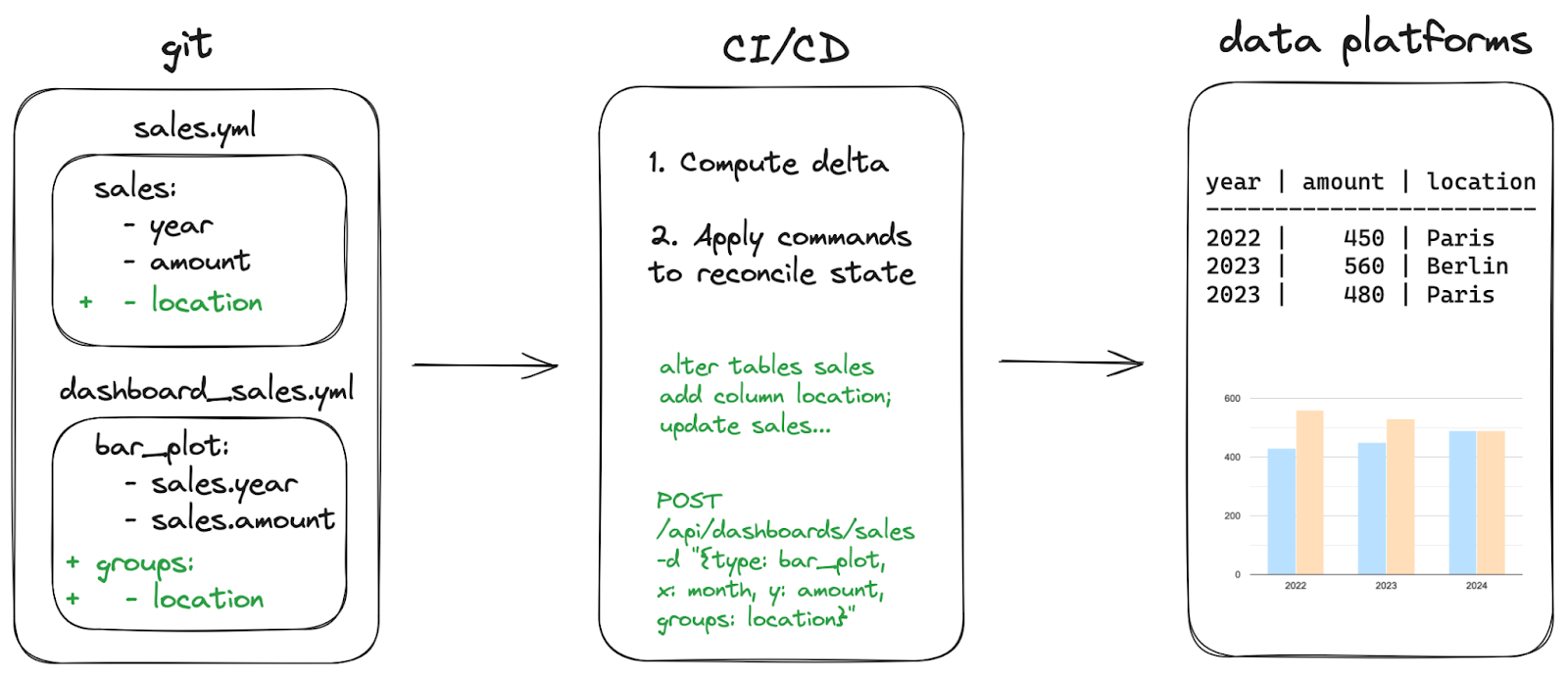
Today’s declarative tool stack
The following (incomplete) list illustrates the declarative trend with various components in the data ecosystem:
- Data materialization. Leaving aside the SQL part which we covered already, dbt uses YAML to let users declare how a table should be materialized, documented, and tested. Declarative model metadata tells dbt everything it needs to know to keep tables fresh and correct. SQLMesh follows a similar approach, albeit with its own configuration language based on SQL.
- Infrastructure. The days of spinning up infrastructure by hand are long gone. Terraform uses HCL (a configuration language loosely similar to YAML or JSON) to declare the state of the desired infrastructure and will figure out the right API calls to reach that state. Connectors exist for virtually all target systems, including most data platforms. When it comes to managing distributed systems, Kubernetes and Docker Compose are also declarative and use YAML to describe the desired properties of those systems.
- Pipelines. A data pipeline is usually a DAG (directed acyclic graph) of steps through which data flows. Orchestrators for data pipelines are increasingly more declarative. Dagster implements the concept of declarative data assets: users specify freshness requirements for pieces of data, and the scheduler takes the right decision to bring the system to this desired state. Argo Workflows builds on top of Kubernetes to let users describe DAGs of pods in YAML, with all their properties and dependencies. Similarly, Hoptimator allows building Kubernetes pipelines for various backends using a single YAML file. Kestra is using YAML to declare data workflows. While Airflow (probably the most famous workflow orchestrator) and Prefect are primarily imperative systems, they do make use of Python decorators to bring some declarativeness to their models.
- Data integration. Through the use of standardized components (taps and targets), Singer built an ecosystem suitable to move all kinds of data from any source to any destination. Building on top of it, Airbyte and Meltano provide user-friendly management. Airbyte encourages the use of Terraform to handle state, while Meltano uses YAML configuration files — both are declarative. Airbyte goes even further by providing a mechanism to declaratively create new connectors.
- Data contracts. Closely tied to data integration concerns, data contracts are naturally declarative, as they describe expectations regarding data shapes and constraints. Paypal’s data contract template uses YAML, as does the data contract specification.
- Semantic layer. Being by nature descriptive, a list of standardized metrics and dimensions fits very well with declarative languages. dbt uses YAML for this purpose, and so does cube in a similar fashion. Data visualization platforms also implement semantic layers, for example Google Looker uses LookML, and Lightdash uses YAML.
- Dashboards and charts. Despite having strong roots in interactive UI environments, even data visualizations can be declarative. For example, Superset supports dashboards as code in JSON. Vega-Lite allows to describe charts with JSON, while DashQL enhances SQL for that purpose. Rill also embeds dashboard definitions in YAML files. On the proprietary side, Google LookML can fully describe dashboards, and Tableau has an entire declarative language to represent data, VizQL.
Those systems already cover a large part of the data engineering stack, but there’s more, see for example how dbt emphasizes declarative tests for data observability and quality, or leverages metadata to build a data catalog.
Is this all just configuration?
In a way, yes. We’ve delegated complex logic and state manipulations to specialized tooling. This is a good thing: it facilitates integrations between different system components, greatly reduces the potential for bugs, and makes it easy to implement GitOps for data products, not to mention the increased developer productivity when it comes to authoring or reviewing changes.
This also helps democratize data systems: the barrier to entry is reduced when someone just needs to tweak YAML files and witness the magic happening behind the curtains.
Writing YAML files is of course boring and not very creative. This was never the goal, just the means towards lean data platforms. Declarativeness is there to free up some time, not be the core job. If data practitioners can reason about data in an easy manner, they communicate more effectively, break less systems, automate migrations, and dedicate time to what matters more (which of course differ widely depending on their role, but “having to deal with an inconsistent state” is rarely exciting).
Embracing a declarative data stack
While the “modern data stack” has seen some hype, controversy, and confusion, it is easy to recognize the data landscape has evolved a lot in recent years, solving some fundamental problems along the way. Declarativeness is essentially abstracting away the complexities of state management, and this approach can be found in many tools of today’s data ecosystem. It easily scales with more data and more users.
So, what comes next? Data platforms adopting declarativeness leads to a fragmentation of YAML files: each tool comes with its semantics, and pipelines, data models and other entities become scattered in multiple locations. While a unique entry point to multiple systems could improve the situation, nailing the right abstraction is always challenging. I’m also curious to see if one platform will emerge to be the metadata container for all platforms (for example, Dagster already uses dbt’s "https://docs.dagster.io/integrations/dbt/reference" target="_blank" rel="noopener" data-href="https://docs.dagster.io/integrations/dbt/reference">meta), or how coupling and integration between different tools will evolve.
In the meantime though, the source of truth is unique. Embrace those YAML files, let the state magically flow, and use that freed-up time to fix those dashboar



 Leah Bekkering
Leah Bekkering